


大家好,今天我们要聊的是一篇关于LLM的论文,主题是如何让大模型的“思维链”(Chain-of-Thought, CoT)变得更高效。大家都知道,大模型在处理复杂问题时,会生成一系列的推理步骤,这就是所谓的“思维链”。虽然这种推理方式很强大,但随着推理步骤的增加,生成的token数量也会直线上升,导致推理速度变慢,用户体验变差。想象一下,你问大模型一个问题,结果它给你吐出一篇“论文”那么长的推理过程,你是不是会有点崩溃?

论文:TokenSkip: Controllable Chain-of-Thought Compression in LLMs
地址:https://arxiv.org/pdf/2502.12067
这篇论文的作者们发现,其实并不是所有的token都对推理结果有同等贡献。有些token是“划水”的,完全可以跳过!于是,他们提出了一个叫TokenSkip的方法,让大模型在推理时能够自动跳过那些不重要的token,从而实现可控的思维链压缩。这样一来,推理速度提升了,用户体验也更好了,简直是一举两得!
方法:TokenSkip – 让大模型“跳”起来!
那么,TokenSkip到底是怎么做到的呢?让我们来一探究竟!
核心思想:不是所有token都重要!
首先,作者们发现,思维链中的token并不是平等的。有些token对推理结果至关重要,比如数学公式和关键数字;而有些token则相对“划水”,比如一些连接词(如“所以”、“因为”)。基于这个发现,TokenSkip的核心思想就是:让大模型学会跳过那些不重要的token,只保留关键的推理步骤。
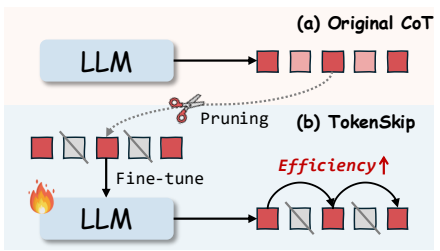
对比了普通CoT和TokenSkip的生成过程,生动展示了“跳过冗余token”的效果。
具体实现:如何让大模型学会“跳”?
TokenSkip的实现分为三个步骤:token修剪、训练和推理。
Token修剪:首先,TokenSkip会根据每个token的语义重要性进行排序,然后根据设定的压缩比例,保留最重要的token,去掉那些“划水”的token。这个过程就像是在修剪一棵树,去掉多余的枝叶,保留主干。

不同token重要性评估方法的对比,帮助理解哪些token被判定为“不重要”。
训练:接下来,TokenSkip会用修剪后的思维链数据对大模型进行微调。为了让大模型学会在不同的压缩比例下工作,训练数据中会包含不同压缩比例的思维链。这样一来,大模型就能学会在不同的压缩比例下进行推理。
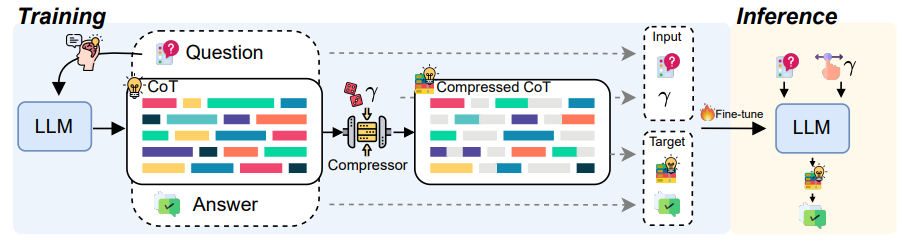
TokenSkip的训练和推理流程,清晰解释了数据压缩和模型适配的过程。
推理:在推理阶段,TokenSkip会让大模型根据设定的压缩比例,自动跳过那些不重要的token,生成压缩后的思维链。这样一来,推理速度就大大提升了!
实验:TokenSkip真的有效吗?
为了验证TokenSkip的有效性,作者们进行了一系列实验,主要使用了两个数学推理基准数据集:GSM8K和MATH-500。实验结果表明,TokenSkip在压缩思维链的同时,依然保持了强大的推理能力。
实验结果:压缩40%,性能几乎不降!
在GSM8K数据集上,Qwen2.5-14B-Instruct模型在使用TokenSkip后,推理token数量减少了40%(从313个减少到181个),而性能下降不到0.4%!这意味着,TokenSkip不仅大幅提升了推理速度,还几乎不影响模型的推理能力。
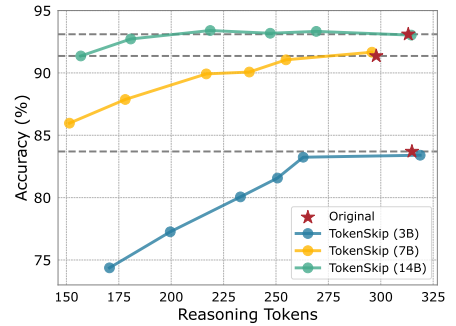
不同压缩比例下的性能变化,直观体现“压缩不降精度”的优势。
对比实验:TokenSkip完胜其他方法!
作者们还对比了TokenSkip和其他两种常见的长度控制方法:基于提示的压缩和截断法。实验结果显示,基于提示的压缩方法无法达到指定的压缩比例,而截断法虽然能压缩token数量,但会导致推理性能大幅下降。相比之下,TokenSkip不仅能够精确控制压缩比例,还能保持较高的推理性能。
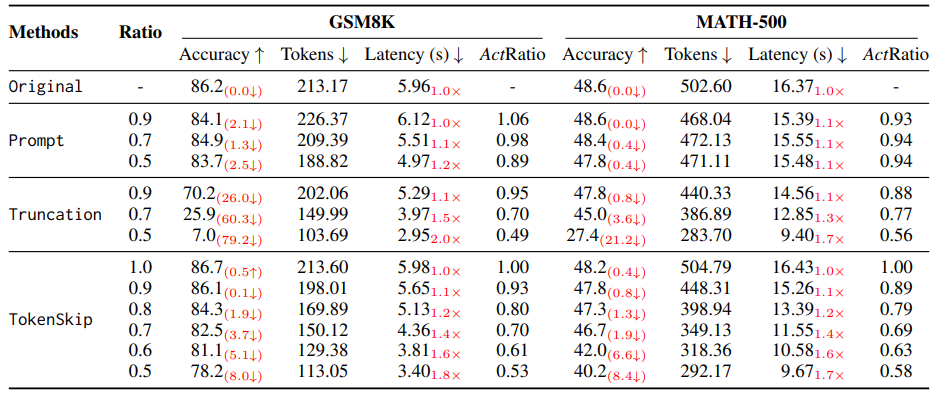
对比了不同方法的性能,TokenSkip在压缩比例和准确率上全面领先。
案例分析:TokenSkip如何“跳”过冗余token?
为了更好地理解TokenSkip的工作原理,作者们还提供了一些案例分析。在这些案例中,TokenSkip成功地跳过了那些不重要的token,比如一些连接词和冗余的句子,而保留了关键的数学公式和数字。这些案例表明,TokenSkip并不是简单地缩短思维链,而是学会了在关键推理步骤之间“跳”过冗余信息。
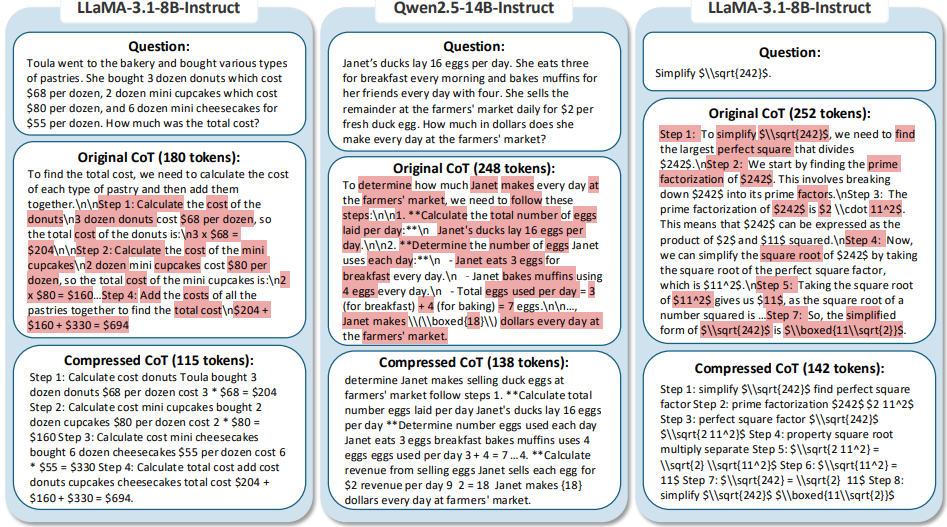
实际案例中TokenSkip的压缩效果,生动体现“跳过划水token”的逻辑。
结论:TokenSkip – 让大模型推理更高效!
总的来说,TokenSkip通过让大模型学会跳过不重要的token,实现了思维链的可控压缩。实验结果表明,TokenSkip在压缩token数量的同时,几乎不影响模型的推理性能,大大提升了推理速度。对于那些需要快速响应的应用场景,TokenSkip无疑是一个非常有用的工具。
(文:机器学习算法与自然语言处理)