


Reinforce++ 和 GRPO 都是 PPO 的变体。PPO 有 4 个模型,actor,critic,reference,reward。
其中 actor 和 critic 都是需要训练并更新参数的模型,而且二者大小差不多,非常占显存,很难 scaling(比如 deepseek v3 600B,训练一个 600B 就已经巨难了,同时训练两个 600B,会不会疯!)。
所以以往好多都是用 DPO,它只需要一个 actor,一个 reference,但是它效果不如 PPO。
有人提出 DPO 的升级版本,让模型自己一个 prompt 输出 n 条,用 reward model 取最好的和最差的两条去训练,迭代几次(iterative 和 reject sampling)。但 DPO 还是不如 PPO,这点大家已经是公认的了。
针对这种问题,业界的共识是去掉 PPO 的 critic 模型,这样就只有一个 actor 是训练模型,ref 和 reward 是推理模型。
推理模型就很好解决了,你甚至可以用一个远程的 url 模型,这就能让 infra 工程师少很多痛苦,也能省很多钱。那么比较有代表性的算法就是 Reinforce++ 和 GRPO。
我们还是要从 PPO 讲起,要引用好多好多来自下面文章的内容:猛猿:人人都能看懂的 RL-PPO 理论知识。


如果完全用实现方式 2,那么就是累积奖励,代表未来奖励的加权和,如果远程奖励还有衰减,那么就是 G_t,也就是熟知的累积折扣奖励。
这类估计价值的办法也叫蒙特卡洛方法。它的特点是偏差小,方差大。它不需要 critic 模型。

如果完全用实现方式 6,那么就是 TD 方法,时序差分,它用 critic 估计 V(s_t),特点是偏差大,方差小。


既然我们想删掉 critic model,那么自然可以从 GAE 退化到完全用 2 来估计价值,就变为累积折扣奖励,也就是 reinforce 用的估计价值的方法。
但是呢,PPO 的一些非常重要的 trick,重要性采样、clip、归一化等等仍得到了保留,因此效果仍会不错,就叫 Reinforce++。
openrlhf 中,默认就是 1,TD 误差参与的其实很少。在语言模型中,critic 模型很难训练得特别好,因此它在 GAE 中也不应发挥过多作用,删掉训练的不怎么样的 critic,reinforce++ 效果也还可以。
PPO 和 Reinforce++ 共用的 r_t 的公式如下,它是逐 token 的即时奖励:


从PPO到GRPO
那么怎么再从 PPO 过渡到 GRPO 呢?
首先就是 r(x,y),它只在句子末尾的结束 [EOS]token 位置才能获得,是一个 float 值,相当于我对这整个问答用 reward model 打个分。
reward model 可以是 rule based(写规则,比如写的代码正确就打 1 分,错误就打 0 分,是准确的),也可以是一个神经网络模型。
这个神经网络模型往往是用 BT loss 训练的:

神经网络模型它往往不是很准确,所以 GRPO 的人想了个办法,就是同一个 prompt 输出 n 条(一个 group)不同的 answer,分别求 r(x,y),然后求这些 r(x,y) 的均值和方差,并对 r(x,y) 用这些均值方差进行归一化。
为了方便,我下面仍管这些归一化的 r(x,y) 叫 r(x,y),而 GRPO 中,管它们叫 A_{i,t},优势值。
其实 PPO 和 Reinforce++ 上也要对 r(x,y) 做归一化,只是均值和方差是训练集的均值和方差。
上面讲的是 GRPO 的一个重要的改进,而下面的操作,我就有点迷惑了:

它把 KL 惩罚从 r_t 中拿了出去!


到这里奖励估计中拿掉了 KL,目前还是挺合理的,我们也从 PPO 和 reinforce++ 上推导出来了共享 A_{i,t} 的原因,它对应 gamma=1 的情况,而这就是 PPO 和 reinforce+ 的默认超参数。
但 GRPO 的 KL 处理可能不是很符合 RL 的理论:



初七123334:RLHF 对齐之 REINFORCE++ 算法 – 比 GRPO 稳定比PPO快
GRPO 直接的 kl 惩罚,PPO、Reinforce++ 中,向后的累积 kl 惩罚的区别,我感觉才是最核心的差异。
在图 1 中,我们找不到 GRPO 这种把即时奖励当做累积奖励的方法。我也想吐槽下,GRPO 说这样实现会更简单,但我觉得,就一个累积运算,也不需要神经网络处理,时延上应该完全是可以忽略的,代码上也没有更加简单。

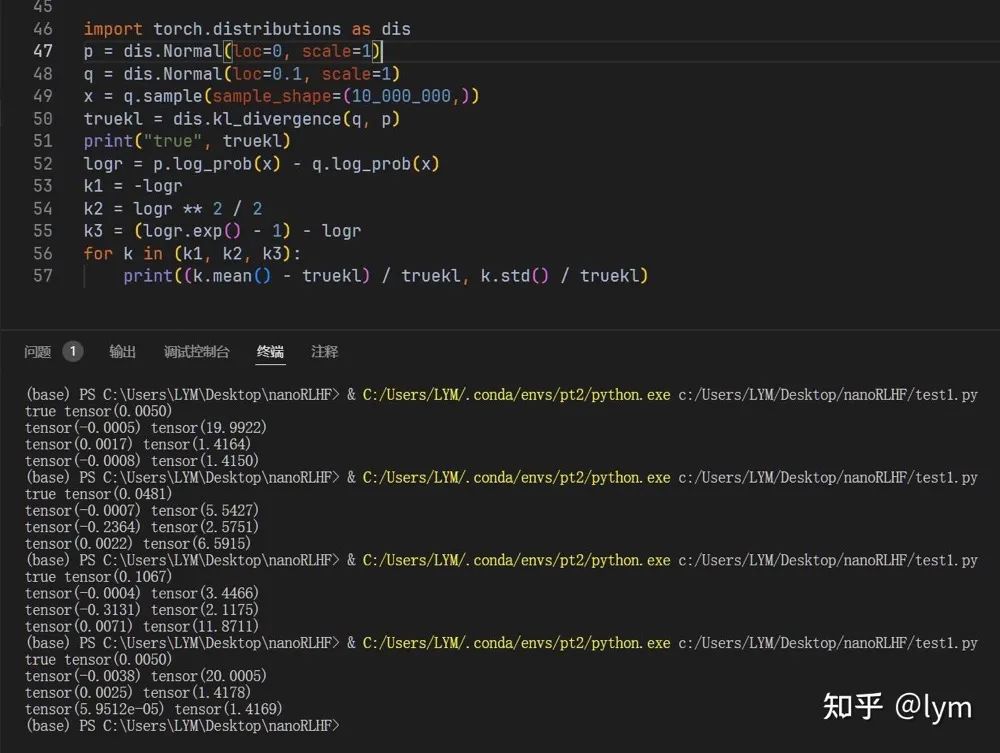
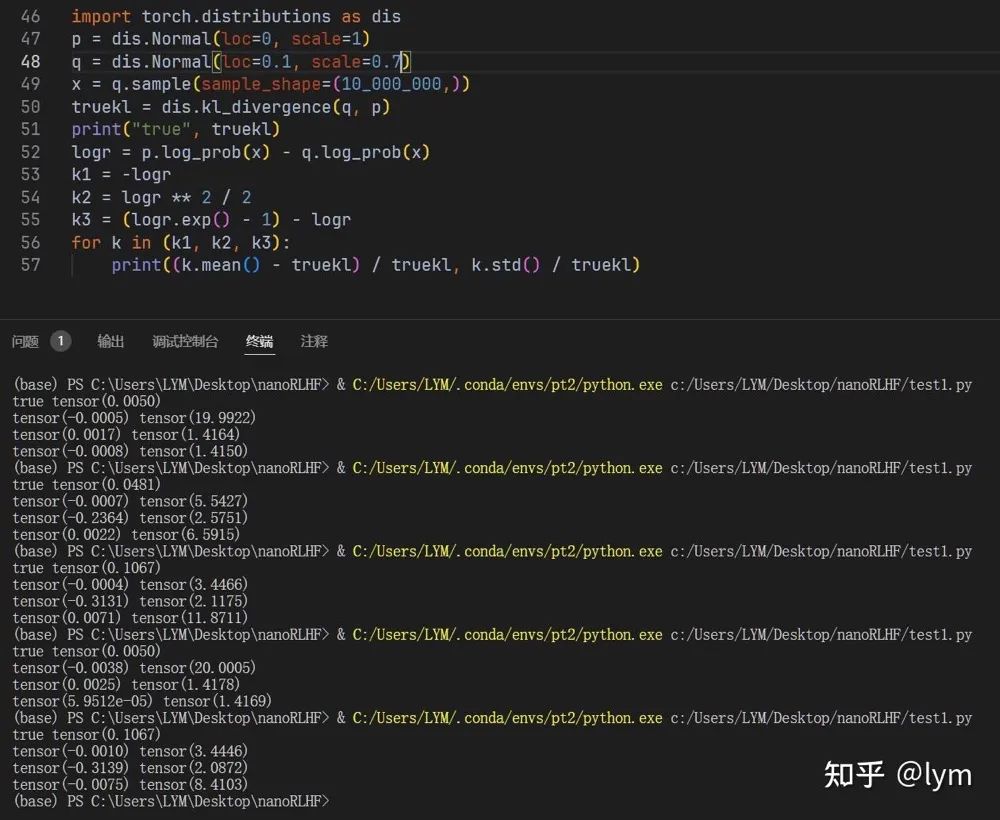
最后 GRPO 中还对 KL 计算进行了优化,John Schulman 的 blog:
http://joschu.net/blog/kl-approx.html




总结
(文:机器学习算法与自然语言处理)