
Midjourney正式推出 V1 视频模型:美学细节无敌

Midjourney发布视频生成模型V1,主打高性价比的动画化图片功能。用户可以通过上传图片创作短视频,支持自动和手动模式、低运动和高运动幅度设置等。工作流程简单易用,可扩展至480p分辨率。
Midjourney发布视频生成模型V1,主打高性价比的动画化图片功能。用户可以通过上传图片创作短视频,支持自动和手动模式、低运动和高运动幅度设置等。工作流程简单易用,可扩展至480p分辨率。

论文提出DRAG框架,通过引入多智能体辩论机制缓解RAG中的幻觉问题。DRAG在检索和生成阶段引入正反方辩论,以提高答案的真实性和可靠性。研究显示,在多个数据集上DRAG取得了强劲表现。

GPT-4o、Claude 等 AI 模型在猜测 1-100 数字时,选择了概率较低的数字 42 和 73。然而,在使用汉语时,多数模型选择了 27,这一现象引起了广泛讨论和研究。

近日MiniMax开启#MiniMaxWeek技术周,发布全新M1模型。M1模型在训练与推理效率上显著提升,支持超长文本输入和输出(最大100万个token)。特别擅长Agent工具调用任务。核心技术包括混合注意力架构和CISPO算法。

Cursor最近更改了其Pro套餐,取消了每月500次快速请求限制,改为所谓的’无限请求’模式。然而,这实际上是限流机制,使用频率过高会导致速度变慢。用户可以选择选择退出新计划回到旧的每日500次快速请求模式。

Meta计划与EssilorLuxottica推出Oakley和Prada品牌的AI智能眼镜。Oakley版本定价360美元,高于Ray-Ban同类产品。此合作标志着Meta首次将硬件推向顶级时尚品牌,与Prada的合作背景是其眼镜授权协议。
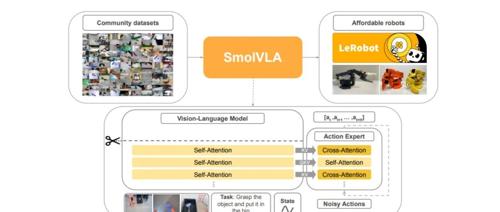
SmolVLA 是 Hugging Face 开源的一个轻量级视觉-语言-行动模型,专为经济高效的机器人设计。它拥有4.5亿参数,能够在消费级GPU甚至CPU上运行,支持在MacBook等设备上部署。通过多模态输入处理、高效推理和异步执行特性,在物体抓取与放置、家务劳动和货物搬运等多种应用场景中表现出色。


