AGICamp 第 002 周 AI 应用榜发布:AiPPT、Lighthouse、SwiftAgent 等上榜

AGICamp 第002周发布了20款新AI应用,涵盖企业端和消费者端。新增的应用包括语音输入法、翻译工具、数据检测系统等,进一步丰富了用户的使用场景和需求。
AGICamp 第002周发布了20款新AI应用,涵盖企业端和消费者端。新增的应用包括语音输入法、翻译工具、数据检测系统等,进一步丰富了用户的使用场景和需求。

近日,中山大学计算机学院与腾讯微信搜索团队联合提出 Q-RM(Q-function Reward Model),在 ICML 2025 正式发表。这一方法专注于构建更精确的 token-level 奖励信号,显著提升了大语言模型的训练效率和效果。

谷歌DeepMind发布了AlphaEvolve模型,这是一个基于Gemini的独特编码代理,可用于设计高级算法、改进AI芯片设计以及解决数学和计算机科学领域中的其他重大问题。该模型展示了自主进化的潜力,并在内部应用中取得了显著效果,同时有望推进更广泛的科研和技术领域的进步。
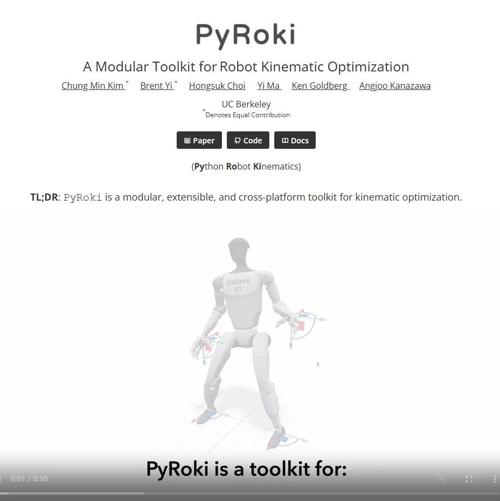
PyRoki 是一个为机器人运动优化设计的Python工具包,支持从URDF文件生成可微分的机器人运动学模型,并自动生成碰撞检测原语和集成Levenberg-Marquardt求解器以提升效率。
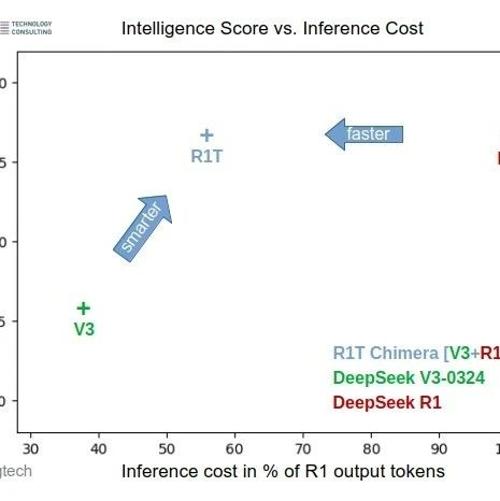
基于DeepSeek-R1微调的DeepSeek-R1T-Chimera模型在保持性能的同时显著缩短了思考时间,可作为DeepSeek-R1的加强版使用。