无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归

首个无监督文本嵌入的跨向量空间转换方法vec2vec提出,无需配对数据就能学习到不同编码器表征间的转换关系。该模型保留了嵌入结构和语义信息,并通过多种损失函数优化性能,在多个数据集上表现优异。
首个无监督文本嵌入的跨向量空间转换方法vec2vec提出,无需配对数据就能学习到不同编码器表征间的转换关系。该模型保留了嵌入结构和语义信息,并通过多种损失函数优化性能,在多个数据集上表现优异。

模型剪枝方法LLM-Streamline通过判断层的重要性,并进行剪枝来减少模型参数量,同时使用余弦相似度和轻量级蒸馏小模型来弥补损失。该方法具有低内存消耗、合理训练方法以及新的稳定性指标等优势,相比已有方法性能更高。

机器学习和数据科学中常用的余弦相似度可能产生不透明且任意的结果。Netflix 和康奈尔大学的研究指出,正则化技术对线性模型的嵌入影响显著,导致余弦相似度不再可靠。研究提出避免余弦相似度使用的方法,并推荐了替代方案如欧几里得距离、点积和归一化等。
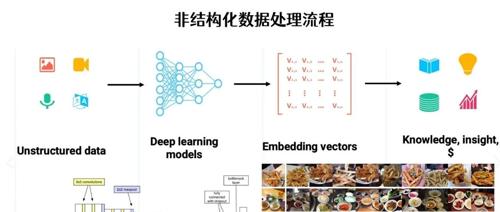
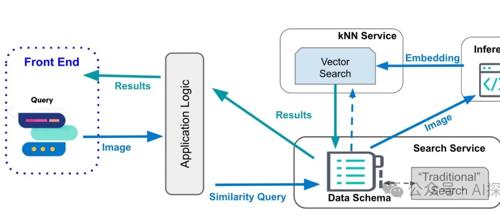
最近研究RAG后思考了嵌入与向量在大模型中的作用;嵌入解决数据向量化问题,向量则描述数据间关系;前者本质上是映射到高维矩阵中以捕捉语义关系,而后者则是数学概念中表示有方向和大小的量。