
强化学习


目标超级智能,前DeepMind科学家离职创业,获1.3亿刀融资

Reflection AI 成立,旨在开发超级智能。该公司已获1.3亿美元融资,估值达5.55亿美元。两名前谷歌DeepMind成员担任CEO和联合创始人,团队包括多名顶尖AI研究人员和工程师。公司目标是开发自主编程工具,并将聚焦于自动执行狭窄的编程任务。
狂揽1.3亿美金!AlphaGo大神组队Gemini大牛,用RL打造超级智能,英伟达抢投

新智元报道:DeepMind老将Ioannis Antonoglou与Gemini核心成员Misha Laskin联合创立Reflection AI,目标构建超级智能自主系统。公司已获得1.3亿美元融资,并计划通过强化学习提升语言模型的自主能力。

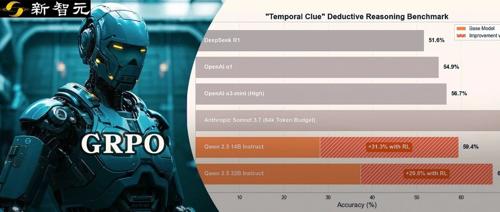
7B的DeepSeek蒸馏Qwen数学超o1!在测试时间强化学习,MIT积分题大赛考93分

DeepSeek研究团队发表LADDER论文,介绍一种通过递归问题分解和强化学习提升AI模型能力的新方法。该方法使7B规模的Qwen模型在MIT Integration Bee比赛中得分达到90分,超越了o1的成绩。
阿里开源推理模型QwQ-32B,实测PK比他大20倍的DeepSeek-R1

阿里巴巴发布全新推理模型QwQ-32B,参数量为32亿,在多项基准测试中与DeepSeek-R1相当或优于OpenAI的模型。展示了出色的逻辑推理、数学分析和知识储备能力,但在处理复杂问题、运用物理知识和理解特定领域概念方面仍有提升空间。
强化学习成帮凶,对抗攻击LLM有了新方法

威斯康星大学麦迪逊分校团队提出了一种使用强化学习对机器学习模型实施黑盒逃避攻击的方法,该方法能够有效生成对抗样本,且无需昂贵的梯度优化。研究发现,在CIFAR-10图像分类任务上,强化学习智能体在训练过程中提高了对抗样本的有效性和效率。
阿里半夜开源全新推理模型,QwQ-32B比肩DeepSeek-R1满血版

阿里开源发布新推理模型QwQ-32B,参数量为320亿。其性能可媲美6710亿参数的DeepSeek-R1满血版。千问团队通过大规模强化学习提升了模型的推理能力,在数学和编程任务上表现优异,并提供了API使用指南。