独家|具身智能新锐「灵御智能」完成千万级种子轮融资,英诺天使基金领投

国内具身智能企业灵御智能完成千万级种子轮融资,以打造实用化标杆为目标,依托清华团队技术积累打通机器人完整智能进化路径。公司推出低成本、高可靠性的数据采集及操作机器人原型机,并在工业、消费等领域应用推广。
国内具身智能企业灵御智能完成千万级种子轮融资,以打造实用化标杆为目标,依托清华团队技术积累打通机器人完整智能进化路径。公司推出低成本、高可靠性的数据采集及操作机器人原型机,并在工业、消费等领域应用推广。
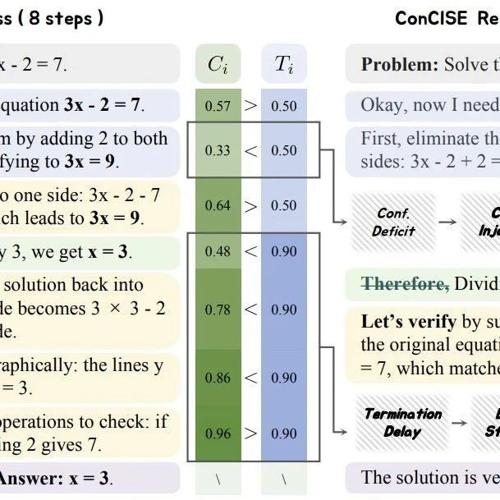
MLNLP社区是国内外知名的机器学习与自然语言处理社区。该社区致力于促进学术界、产业界和爱好者的交流与进步,特别是初学者的成长。最新研究表明,通过信心注入和早停机制,可以显著减少模型的冗余推理步骤,提高准确性而不影响性能。

清华大学团队提出傅里叶位置编码(FoPE),通过鲁棒性强的位置编码克服Transformer在处理长文本时的周期性延拓限制,显著提升模型的长文本泛化能力。

谢赛宁十年前被NeurIPS拒收的论文《Deeply-Supervised Nets》(DSN)今年获AISTATS时间检验奖。该论文提出中间层监督思想,继承并发展了后续作品REPA和U-REPA,对计算机视觉领域产生了深远影响。
清华大学和上海人工智能实验室提出测试时强化学习(TTRL),通过在无标签数据上利用多数投票等方法估计奖励信号来提升大规模语言模型性能。

清华聘任前谷歌DeepMind科学家Alex Lamb为助理教授,美国AI人才反向流动加速。此前他曾看低中国AI研究,现选择加入清华大学。多位美国AI专家表示考虑离开,特朗普政府的移民政策加剧了这一趋势,中国正成为AI人才的主要目的地。

来自清华大学、中国科学院大学、华南理工大学、东北大学的联合研究团队提出了一种全新的适应式RAG方法——DeepNote。它首次引入“笔记”作为知识载体,实现更深入、更稳定的知识探索与整合,在所有任务上均优于主流RAG方法,性能提升高达+20.1%。