
解锁文档处理新高度!这个开源神器支持OCR+机器学习,超丰富的API接口,效率翻倍!
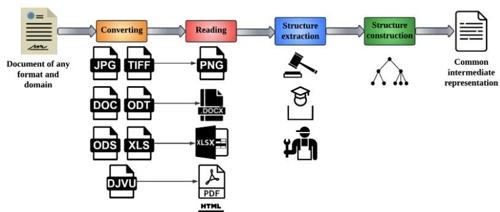
Dedoc是一款ISPRAS团队开源的文档提取与转换工具,支持多格式文档处理,包括Office、PDF和扫描件等,并能智能提取表格、文本格式和逻辑结构。其核心功能亮点涵盖文档逻辑结构提取、复杂表格解析以及OCR扫描件处理。
Dedoc是一款ISPRAS团队开源的文档提取与转换工具,支持多格式文档处理,包括Office、PDF和扫描件等,并能智能提取表格、文本格式和逻辑结构。其核心功能亮点涵盖文档逻辑结构提取、复杂表格解析以及OCR扫描件处理。
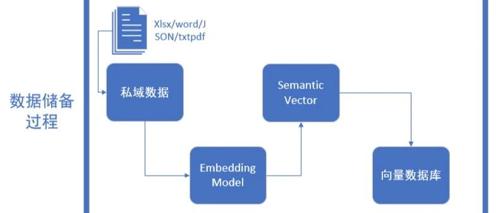
关于RAG在实际场景中的应用,重点讨论了文档处理和高效检索的问题。文档处理涉及多样化和复杂的格式,需要拆分和识别文本、图片和图表等不同内容类型。高效的检索则需利用多种匹配方式(精确字符匹配与语义匹配),通过多路召回策略综合考虑多个维度的数据来优化结果。

Andrej Karpathy 在 YouTube 上发布了一段长达 2 小时的学习视频,详细介绍了如何使用大型语言模型(LLM),涵盖模型生态系统、交互示例和多种应用场景。

STranslate 是一款集翻译和OCR功能于一身的开源工具,支持多种语言翻译、离线OCR识别及多种翻译服务接入。它还具备高级功能如回译、全局TTS等,适用于学习语言、阅读外文资料、语言创作以及提高工作效率等多种场景。

一个基于深度学习的漫画图像翻译工具Manga Image Translator,通过OCR技术识别并翻译漫画中的文字,并无缝嵌入原图中。该项目由作者持续更新维护,支持多种语言和功能选项,目前已有良好效果。
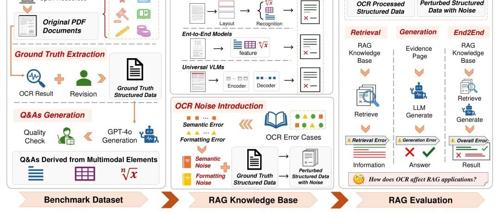
在RAG系统中,基于OCR的非结构化PDF文档抽取导致知识库中的语义噪声和格式噪声问题,影响RAG系统的性能。OHRBench评估了当前OCR解决方案,并推荐使用Marker实现最佳检索性能,但所有解决方案仍存在性能下降。


