
1000万上下文!新开源多模态大模型,单个GPU就能运行

Meta 最新开源模型 Llama 4 Scout 达到千万级上下文,拥有 1090 亿参数。其使用 NoPE 架构解决长度泛化问题,并通过优化训练流程和强化学习框架提升性能。
Meta 最新开源模型 Llama 4 Scout 达到千万级上下文,拥有 1090 亿参数。其使用 NoPE 架构解决长度泛化问题,并通过优化训练流程和强化学习框架提升性能。
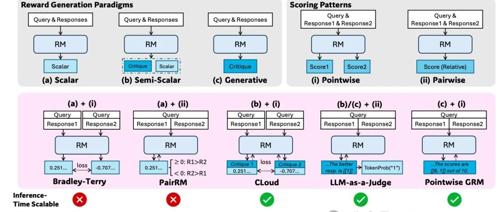
DeepSeek联合清华发布研究成果,提出DeepSeek-GRM模型通过点式生成奖励建模提高通用查询的性能,利用自我原则批评调整等方法实现推理时扩展。该模型在多个基准测试中表现出色,在推理时的性能随着采样数量增加而显著提升。

DeepSeek发布新论文提出SPCT方法解决通用RM推理时扩展问题,并计划先发布o3和o4-mini,GPT-5将在几个月后推出。

DeepSeek与清华大学合作的研究提出了一种通用奖励模型GRM及其改进方法SPCT,通过增加推理计算量实现了有效的推理时扩展,并显著提升了LLM的性能。