
扩散模型

DiffMoE:动态Token选择助力扩散模型性能飞跃,快手&清华团队打造视觉生成新标杆!

本文介绍清华大学与快手可灵团队合作的DiffMoE研究,通过动态token选择和全局token池设计提升扩散模型效率。论文在ImageNet分类图像生成任务中仅用4.58亿参数即超越6.75亿参数的Dense-DiT-XL模型。
AI无限生成《我的世界》,玩家动动键盘鼠标自主控制!国产交互式世界模型来了
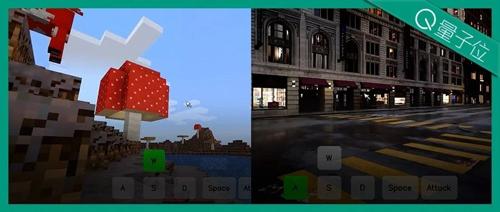
用AI无限扩展《我的世界》,用户通过鼠标键盘即可自由探索、创作高质量虚拟内容,支持8大Minecraft场景生成。Matrix-Game模型在视觉质量、控制能力等方面超越现有开源基线。
开源全能图像模型媲美GPT-4o!理解生成编辑同时搞定,解决扩散模型误差累计问题
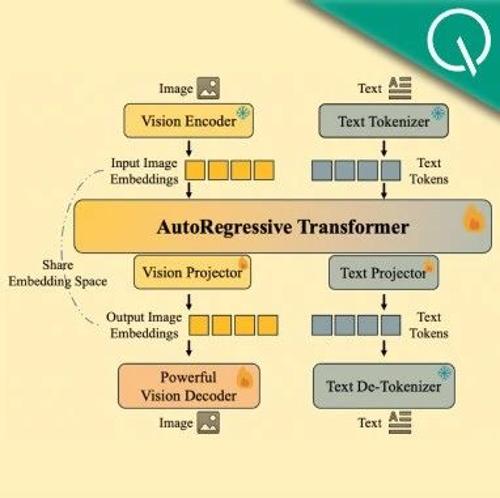
ModelScope团队提出Nexus-Gen统一模型,融合MLMs和扩散模型能力,实现图像生成、理解与编辑。其技术细节包括预填充自回归策略和统一的数据格式定义。模型已在多个任务上取得GPT-4o级效果,并开源了训练数据、工程框架及论文。
2分钟玩转HeyGen最新模型:一张照片+一句话,秒出AI分身!超逼真!

HeyGen发布的Avatar IV模型能通过一张照片、一段脚本和声音生成逼真数字人,支持多角度图像输入,不仅能说还能唱。新引擎根据语音节奏自动生成表情和动作,应用场景广泛。
CVPR 2025 满分论文|收敛速度提升21倍!VA-VAE:重建 vs. 生成,解决 LDM 的优化困境

256 生成上实现了最佳 (SOTA) 性能,FID得分为1.35,同时在短短64个epoch内就达
CVPR 2025 如何稳定且高效地生成个性化的多人图像?ID-Patch带来新解法
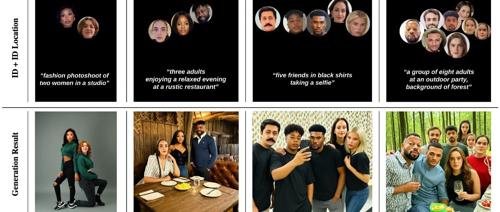
本文提出ID-Patch方案,用于解决多人图像生成中的身份特征泄露问题。通过ID Patch将身份特征转化为小尺寸RGB图像块,精确指定每个人的位置,并与文本提示共同输入增强人物面部真实性。实验结果显示其在身份还原和位置匹配上表现优秀,且生成效率快。
Aether:上海 AI Lab 开源的生成式世界模型,探索三维时空建模与智能决策新境界

上海 AI Lab 开源的 Aether 项目通过三维时空建模和多模态融合技术,实现了生成式世界模型在虚拟数据上的出色表现,并具备对真实世界的零样本泛化能力。
质量无损,算力砍半!达摩院开源视觉生成新架构,出道即SOTA|ICLR 2025

达摩院在ICLR 2025提出了动态架构DyDiT,通过智能资源分配将DiT模型的推理算力削减51%,生成速度提升1.73倍,FID指标几乎无损,并且仅需3%的微调成本。
文本提示、空间映射?任意条件组合都拿下!UniCombine:统一的多条件组合式生成框架

UniCombine 是一种基于 DiT 的多条件可控生成框架,能够处理任意条件组合。它在多种多条件生成任务上达到了最先进的性能,并且构建了首个针对多条件组合式生成任务设计的数据集 SubjectSpatial200K。