
斯坦福等开源代码定位AI Agent,极大提升开发、维护效率
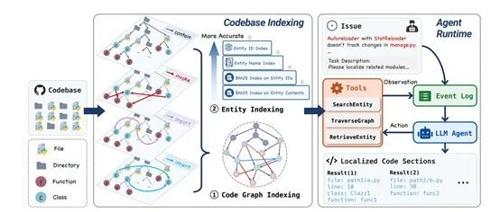
斯坦福大学等研究团队开源了智能体LocAgent,用于解决复杂代码库中的代码定位问题。LocAgent通过图基表示技术捕捉代码结构和依赖关系,并利用稀疏层次实体索引快速搜索与问题描述相关的代码片段。
斯坦福大学等研究团队开源了智能体LocAgent,用于解决复杂代码库中的代码定位问题。LocAgent通过图基表示技术捕捉代码结构和依赖关系,并利用稀疏层次实体索引快速搜索与问题描述相关的代码片段。

alphaXiv 推出的新功能「Deep Research for arXiv」协助研究人员更高效地检索和阅读学术论文,显著提升文献研究效率。

近期开源的OpenVLA模型通过高效的参数利用和卓越性能推动了机器人技术的发展。基于Llama 2语言模型和融合视觉编码器,它能够将自然语言指令转化为精确的机器人动作。支持在消费级GPU上进行微调,并实现高效服务。应用场景包括家庭服务机器人、工业机器人及教育研究等领域。

最新研究发现,LLM在人格测试中会自我调整以符合外向性和宜人性得分,表现出与人类相似的讨好行为倾向。但这种「讨好」可能掩盖问题本质,引起用户信任危机。
AI销售代表初创企业市场竞争激烈。Actively AI公司采用推理模型帮助企业筛选最有价值的销售目标,该公司已完成2250万美元融资,旨在通过自动化或辅助方式推动增长。

刚起床就看到OpenAI CEO山姆·奥特曼换新头像引发网友设计狂欢。网友们纷纷创作各种风格山姆形象,从吉卜力、GTA游戏至黑暗风等,展现了极强的创意与想象力。

人形机器人通过斯坦福大学ALOHA团队开发的人形模仿框架HumanPlus实现了高效控制和模仿学习,为服务机器人、工业自动化、教育及医疗康复等领域提供了新工具。


