
大模型
大语言模型

DeepSeek-R1、Kimi k1.5、豆包1.5 Pro、GLM,国产AI太燃了!AI Weekly『1月20-26日』

大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研
DeepSeek-R1 vs o1-pro,Grok 3竟成幕后赢家?!

木易在公众号分享了关于国产模型DeepSeek-R1和老牌强手o1之间的比较,并引入了更高算力的o1-pro。近期,Eric Zelikman对Grok 3进行了测试,结果表明Grok 3在碰撞效果上表现最优,引发热议。
ICLR 2025 自动化所、旷视等提出Ross,多模态大模型的MAE时刻来了?

本文介绍了一篇关于多模态大模型的研究论文《Reconstructive Visual Instruction Tuning》,提出通过重建输入图像作为监督信号来提升视觉部分的学习效果,显著提高模型的细粒度理解能力,并且代码已开源。


关于神经网络的一些思考与感受
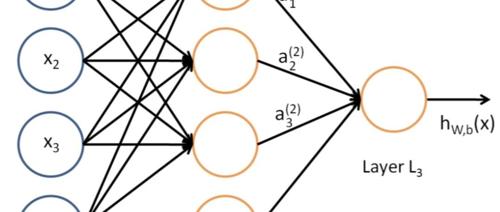
文章讲述了神经网络模型的重要性以及设计不同类型模型来解决不同问题的必要性。文章还提到了训练数据的质量和使用TensorFlow或PyTorch框架的技术实现,强调了实践对于理解神经网络运作机制的重要性。
“洋悟运动”+“深海巨鲸”:当世界开始仰望中国制造!

木易创建了‘AI信息Gap’公众号,专注于分享AI知识。2025年1月,小红书因用户激增和TikTok禁令引发流量爆发,并被网友戏称为‘洋悟运动’。DeepSeek发布新模型后引起广泛关注并决定开源。文章认为这体现了中国科技的崛起与开放精神。

无需RLHF显著提升GPT-4性能,北大团队提出对齐新范式「残差修正」 NeurIPS 2024 Oral

学习对齐答案和未对齐答案之间的残差,要比直接学习问题到答案之间的映射更容易。
背景
当下大语言模型(