
月度归档: 2024 年 12 月

AAAI 2025 SparseViT:参数高效的稀疏化视觉Transformer
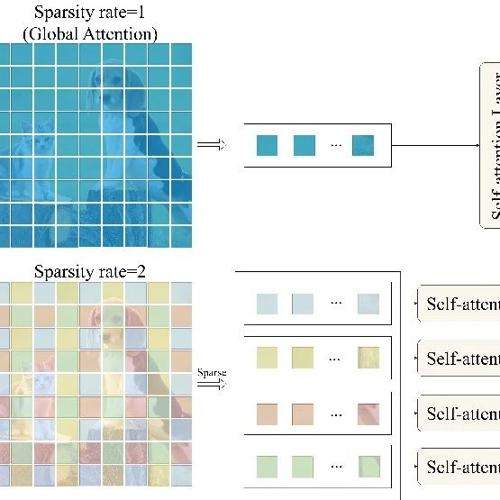
四川大学吕建成团队与澳门大学合作提出SparseViT,这是一种针对图像篡改检测的稀疏化视觉Transformer。通过稀疏自注意力机制和可学习的多尺度监督机制,实现了对非语义特征的自适应提取,并在多个基准数据集上展现了卓越性能。
Adobe再来! 新 AI 工具允许声音设计师通过哼唱和模仿声音来创建音频

Adobe研究团队开发的Sketch2Sound通过声音模仿和文本描述生成专业的音效和氛围音,降低音效创作门槛,提高工作效率,并广泛应用于音乐创作及拟音师工作。该系统能精准捕捉和分析响度、音色和音高等关键要素,具备智能化上下文理解能力,内置过滤技术满足专业人士需求。
导师放养,拿下SCI论文
20年老牌辅导机构沃恩智慧提供学术背景提升服务,包括SCI/CCF论文撰写与修改。导师来自QS前100高校或教授,提供从选题到发表的全方位科研支持,保障学员权益。现免费赠送SCI写作系列课和申研申博攻略课程。


这个让AI 能自我检验的智能体,解决了AI 决策脱节的问题
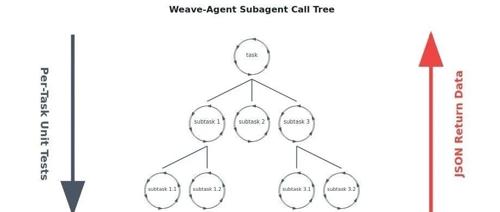
AI智能体开发者John David Pressman推出Weave-Agent架构,解决了传统ReAct智能体决策脱节问题。通过增加单元测试回调机制、递归分解复杂任务及提供MiniHF工具套件,实现AI自我检验和简单部署。


ViT作者飞机上也要读的改进版Transformer论文,花2个小时详细批注解读分享出来
Lucas Beyer分析了微软提出的DiffTransformer论文,指出其通过两个注意力头的差值来改善Transformer模型信噪比的问题。尽管存在一些质疑,Beyer认为该方法具有简单而有效的创新点,并强调需要更多图表和实验结果以验证其潜力。