
103K「硬核」题,让大模型突破数学推理瓶颈

本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。
本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。

华为首次展示了其‘数字化风洞’技术,通过虚拟环境平台在电脑中预演复杂AI模型的训练和推理过程,以避免算力浪费。该技术包括Sim2Train用于优化训练阶段配置、Sim2Infer提升推理性能至30%以及Sim2Availability确保大模型高可用性。

VRAG-RL 是一种基于强化学习的视觉检索增强生成方法,通过引入多模态智能体训练,实现了视觉语言模型在检索、推理和理解复杂视觉信息方面的显著提升。

欧洲人工智能公司 Mistral AI 推出了 Magistral 系列大语言模型,具备强大的推理能力。Magistral Medium 和 Magistral Small 分别面向企业客户和开源社区,支持 Apache 2.0 许可,并在多种测试中表现出色。

研究构建首个面向MLLM的细粒度AES基准EssayJudge,采用10项细粒度评分维度,涵盖词汇、句子和文章三个层级,评价作文质量。
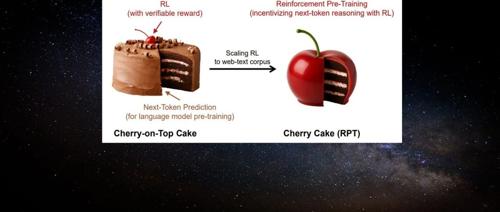
机器学习研究者提出一种名为”强化预训练”的新方法,它将下一个 token 预测任务重构为对 next-token 的推理过程。通过可验证奖励的强化学习,这种方法利用海量无标注文本数据进行通用预训练,显著提升语言建模准确性,并有望推动大模型发展的有效路径。

文章介绍了如何通过掌握正确的科研方法和导师指导快速发表顶会顶刊论文。强调了执行能力和实战经验的重要性,并推荐了一堂由顶级期刊主席主讲的系统课程,涵盖了论文选题、写作与投稿全流程的知识点和方法论。

文章介绍了Claude Code作为强大的AI编程工具的优点和局限性,并提出使用DeepSeek或类似模型通过claude-bridge实现成本更低的解决方案。

微软首席商务官透露,一家拥有超过100万个Microsoft 365许可证的大客户即将为其员工增购Copilot服务。预计该交易将为微软带来数亿美元收入,并推动AI工具的应用普及。
