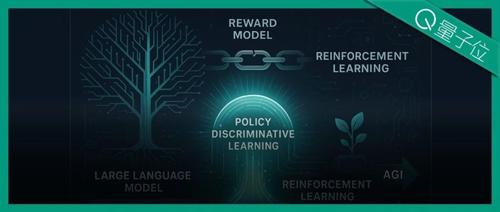
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式 2025年7月11日16时 作者 量子位 已成为AI迈向AGI进程中的关键技术节点。 然而,其中 奖励模型 的设计与训练,始终是制约后训练效果
OpenAI去年挖的坑填上了!奖励模型首现Scaling Law,1.8B给70B巨兽上了一课 2025年7月11日16时 作者 新智元 性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注
奖励模型终于迎来预训练新时代!上海AI Lab、复旦POLAR,开启Scaling新范式 2025年7月10日16时 作者 机器之心 望迈向 AGI 的核心方法。然而,奖励模型的设计与训练始终是制约后训练效果的关键瓶颈。 目前,主流的
8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂 2025年6月9日11时 作者 HyperAI超神经 AI 研究所与硅谷 Cerebras Systems 公司的联合研究团队开发了 Prot42 ——首
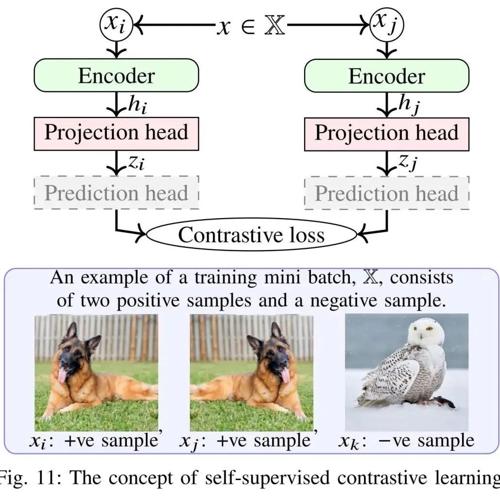
用于图像分割的自监督学习(Self-Supervised Learning)方法综述 2025年5月26日23时 作者 极市干货 监督学习在图像分割领域的应用进行了全面综述,分析了从传统方法到自监督学习的演进路径,介绍了预测型、生
Yann LeCun 不行了吗? 2025年2月10日8时 作者 AGI Hunt Meta首席AI科学家Yann LeCun提出转向联合嵌入架构、拥抱基于能量的模型等路线图,遭业界质疑。他主张放弃生成模型、对比学习和强化学习,引发争议。
DA-CL-4Rec:这是一个专注于推荐系统领域的研究进展收集库 2025年1月20日8时 作者 NLP工程化 DA-CL-4Rec:一个收集推荐系统领域最新研究进展的库,涵盖对比学习、数据增强和自监督学习。