
GPT-5研发内幕首曝!OpenAI首席研究官:AGI指日可待

GPT-4.1的核心研究员Michelle Pokrass透露,构建GPT-5的挑战在于在推理和聊天之间找到平衡。OpenAI首席研究官Mark Chen表示,AGI不仅是ChatGPT,还包括其他方面,并强调了平衡短期产品发布与长期研究的重要性。
GPT-4.1的核心研究员Michelle Pokrass透露,构建GPT-5的挑战在于在推理和聊天之间找到平衡。OpenAI首席研究官Mark Chen表示,AGI不仅是ChatGPT,还包括其他方面,并强调了平衡短期产品发布与长期研究的重要性。
MLNLP
社区致力于推动国内外自然语言处理与机器学习领域的交流合作。近期,
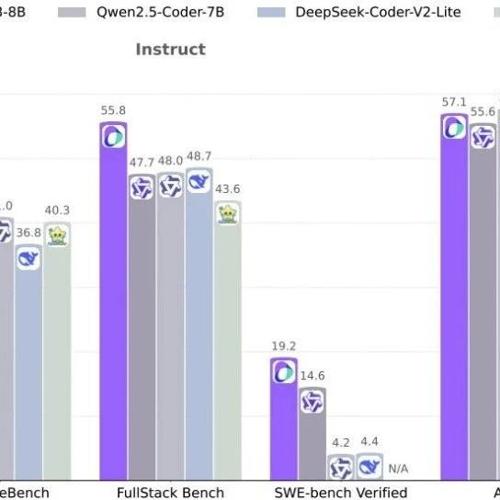
Seed-Coder团队开发了一种能自我筛选数据的代码模型,该模型在多个测试中表现优异。

LlamaCon。现场,该公司宣布推出一款面向消费者的独立 Meta AI 聊天机器人应用程序,这款
Lightricks 发布开源视频生成模型 LTXV-Video-13B,支持多尺度渲染、高级控制等特性,可完全商业使用。
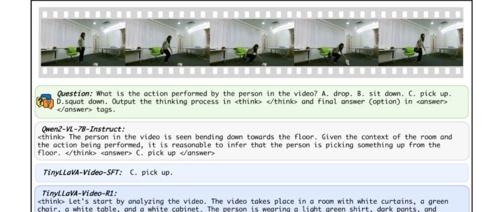
北京航空航天大学推出的小尺寸视频推理模型TinyLLaVA-Video-R1通过强化学习显著提升了小规模模型的性能,并开源了权重、代码和训练数据。该模型参数量不超过4B,在多个基准测试中表现优异,具备强大的多模态理解能力和可解释性生成能力。
微软推出免费生成式AI入门课程,涵盖基础原理到实战项目全流程,支持Python和TypeScript编程语言,还提供后续对接服务、官方社群交流等资源。

阿里开源最新大模型Qwen3,在多个测试平台上超越知名模型。Qwen3支持多种语言和方言,覆盖119种语言,包含2个MoE模型权重及6个Dense模型。其预训练数据集庞大,涵盖36万亿token,性能与Qwen2.5相当甚至超过。


