
DeepSeek开源周五大兵器

FlashMLA发布首日即引发广泛关注,通过智能调度大幅提升GPU利用率;DeepEP优化MoE模型通信效率;DeepGEMM实现高效FP8矩阵乘法,性能接近专家调优库;DualPipe+EPLB双剑合璧提升并行计算效率至30%以上;3FS文件系统进一步加速AI数据访问速度。
FlashMLA发布首日即引发广泛关注,通过智能调度大幅提升GPU利用率;DeepEP优化MoE模型通信效率;DeepGEMM实现高效FP8矩阵乘法,性能接近专家调优库;DualPipe+EPLB双剑合璧提升并行计算效率至30%以上;3FS文件系统进一步加速AI数据访问速度。

专注AIGC领域的专业社区分享了开源优化并行策略DualPipe和EPLB。DualPipe用于V3/R1训练中减少流水线气泡,显著提高效率;EPLB通过动态调整专家负载保持平衡,避免通信开销增加。

款“全新”、非官方规格的显卡。淘宝厂家甚至给出了基础款和升级款两种选择,其中基础款用的是拆机进口颗粒

DeepSeek的开源周Day2发布了DeepEP库,这是一个为MoE模型训练和推理定制的通信库,支持高吞吐量、低延迟的All-to-All GPU内核,并提供针对非对称域带宽转发优化的内核。
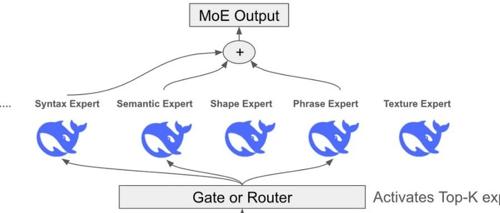
DeepSeek 开源周第二天,带来了 DeepEP 通信库,旨在优化混合专家系统和专家并行模型的高效通信。其亮点包括高效的全员协作通道、专为训练和推理预填充设计的核心以及灵活调控GPU资源的能力,显著提升MoE模型的性能和效率。

DeepSeek 开源首个用于MoE模型训练和推理的EP通信库 DeepEP,优化高效通信和并行处理,支持FP8精度,并提供灵活资源调度。
DeepSeek OpenSourceWeek 发布了首个面向MoE模型的开源EP通信库 DeepEP。它提供了高性能All-to-All通信内核、集群内和集群间全面支持,以及训练和推理预填充及推理解码低延迟内核等特性。性能测试显示其在不同场景下都能提供出色的通信性能。

DeepSeek本周发布的新版本DeepEP为混合专家模型提供高效的通信解决方案,支持Hopper GPU架构。通过优化的核心、低延迟操作和创新的通信-计算重叠方法提升了模型在训练和推理阶段的性能。

