
强化学习

滚烫Deepseek一夜刀掉英伟达4万亿,除夕开源多模态新模型:7B超越DALL-E 3和StableDiffusion
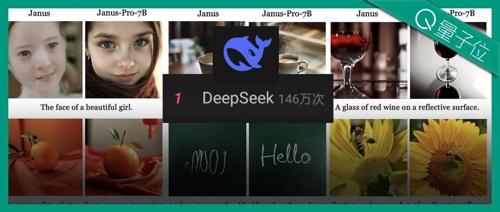
DeepSeek发布新模型Janus-Pro-7B,击败DALL-E 3和Stable Diffusion,在GenEval和DPG-Bench基准测试中表现优异。该模型基于自回归框架设计,采用SigLIP-L视觉编码器进行多模态理解和生成。
DeepSeek-R1解读:纯强化学习,模型推理能力提升的新范式?

LLM模型通过纯强化学习提升推理能力,并提出无需监督数据的新方法。端侧模型性能提升主要依赖蒸馏而非强化学习,DeepSeek-R1-Zero展示了自我进化能力及语言一致性奖励的应用。
R1风起,清华、港科大发布大模型强化推理技术最新全面综述

本文回顾了大型语言模型在推理能力方面的最新进展,从SFT到RLHF,再到ORM和PRM等技术的演变,讨论了测试时扩展的重要性,并介绍了各种增强LLMs推理能力的技术方法。


中国AI太强,Meta工程师吓疯?自曝疯狂熬夜复制DeepSeek,天价高管心虚了

Meta员工在TeamBlind上爆料,DeepSeek公司训练成本仅550万美元就推出了性能堪比OpenAI的AI模型。这令Meta高管们感到尴尬和紧张,Meta工程师也正在争分夺秒地分析DeepSeek的技术细节。
OpenAI智能体Operator背后CUA技术解析

智谱、ByteDance和清华大学发布GLM-PC等智能体后,OpenAI发布了首个AGI L3级智能体Operator,可以执行网络任务并交互网页。Operator结合了GPT-4的视觉能力和强化学习推理能力。构建开源Computer-Using Agent的技术挑战包括安全隔离、精确点击、视觉理解和部署LLM等。