
强化学习

突发!OpenAI 刚刚发布代理Operator:AI进入Level 3,但只有美国Pro用户可以试用
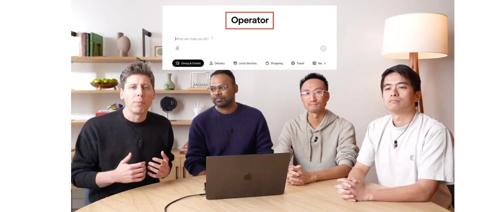
OpenAI 推出名为Operator的研究预览版代理,能够像人类一样浏览网页并执行各种在线任务。这款工具结合了GPT-4o的视觉能力和强化学习,支持WebArena和WebVoyager基准测试领先水平。它具备自我纠错能力,并且允许用户个性化工作流程。OpenAI计划将其公开于API中并扩大访问权限。
2分钟完成论文调研!ByteDance Research推出论文检索智能体PaSa,远超主流检索工具

ByteDance Research 推出的学术论文检索工具PaSa,在复杂的学术搜索场景中展示了显著优势,相比主流检索工具和强化学习模型均有提升。
正面硬刚OpenAI现役最强模型,国产AI一夜卷到硅谷

中国双子星DeepSeek和Kimi发布全新推理模型R1和k1.5,性能接近OpenAI o1,引发业界关注。Long2Short训练方案成为亮点,提升了短推理路径模型的性能。
在可以 RL 的地方,将迎来更多「李世石时刻」

Kimi 和 DeepSeek 通过 RL 技术分别在 short-CoT 和 long-CoT 模式下取得了出色表现,并提出了一些关键技术,如 Partial rollouts 来提升训练效率和长 CoT 数据涌现机制。该领域的发展显示了 AI 在复杂任务中的潜在能力。
国产模型如何追上多模态OpenAI o1?你需要知道的全在这

Kimi 团队发布了最新的多模态推理大模型 Kimi k1.5,其性能与正式版 o1 最为接近。通过 Long2Short 技术,该模型能够在有限的 token 预算下实现高性能推理,提升用户体验和资源利用效率。
DeepSeek R1 训练方法解析

DeepSeek AI 推出 DeepSeek-R1 模型,引入群体相对策略优化(GRPO)和多阶段训练方法。通过强化学习提升大语言模型推理能力,并在监督微调和拒绝采样后形成最终模型。
DeepSeek开源o1击毙OpenAI,强化学习惊现「啊哈」时刻!网友:AGI来了

中国版o1 DeepSeek R1通过大规模强化学习训练,在多项任务中与OpenAI o1打成平手,展示了不依赖监督微调数据也能显著提升推理能力的潜力。
社区供稿 | ReaderLM v2: HTML 转 Markdown 和 JSON 的前沿小型语言模型

2024 年 4 月,我们发布了 Jina Reader (https://jina.ai/read
DeepSeek-R1与Kimi k1.5深度分析:大模型进化的4大趋势!
木易分享了近期国内大模型圈的最新动态,强调DeepSeek-R1和Kimi k1.5在推理模型上的亮眼表现及技术细节,包括强化学习、长上下文扩展、蒸馏技术和基于规则奖励机制等重要概念。