
清华大学

RAG性能暴增20%!清华等推出“以笔记为中心”的深度检索增强生成框架,复杂问答效果飙升

来自清华大学、中国科学院大学、华南理工大学、东北大学的联合研究团队提出了一种全新的适应式RAG方法——DeepNote。它首次引入“笔记”作为知识载体,实现更深入、更稳定的知识探索与整合,在所有任务上均优于主流RAG方法,性能提升高达+20.1%。
大模型靠强化学习就能无限变强?清华泼了一盆冷水
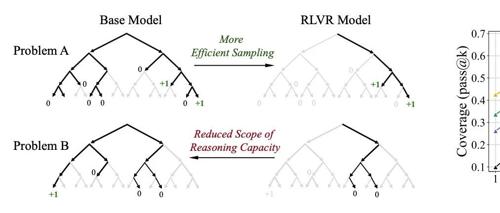
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。
质量无损,算力砍半!达摩院开源视觉生成新架构,出道即SOTA|ICLR 2025

达摩院在ICLR 2025提出了动态架构DyDiT,通过智能资源分配将DiT模型的推理算力削减51%,生成速度提升1.73倍,FID指标几乎无损,并且仅需3%的微调成本。
机器人也会挤牙膏?ManipTrans:高效迁移人类双手操作技能至灵巧手

研究团队提出ManipTrans方法,通过两阶段迁移学习实现从人类手到机械灵巧手的操作技能转移。该方法利用通用轨迹模仿器预训练模型模仿人类手部动作,并引入残差学习模块对动作进行精细调整。同时发布DexManipNet大规模数据集用于验证。
Adam获时间检验奖!清华揭示保辛动力学本质,提出全新RAD优化器

清华大学团队提出RAD优化器,该优化器通过神经网络与共形哈密顿系统的对偶性揭示了Adam的优化动力学机理,并提出了新的Relativistic Adaptive Gradient Descent (RAD)优化算法,实验表明其在多种强化学习任务中表现优于Adam。
用 SurveyGO,像清华团队一样无痛做科研!

清华团队研发的SurveyGO利用AI辅助科研人员提效,自研LMxMapReduce-V2技术解决资源收集问题。产品能生成长篇综述文章,并在多方面优于现有方案。

机器人跑马拉松,到底在比什么?

全球首个‘人机共跑’半程马拉松在北京举行。18款国产机器人参与比赛,单台机器人体关节运动量高达25万次。天工Ultra和N2分别夺得冠亚军。赛事综合检验了机器人的多项技术能力,如精准控制、环境感知与自主决策等。
RL for LLMs,强化学习的 Scaling Law 才刚刚起步?

近期研究者通过奖励模型增强通用奖励模型在推理阶段的可扩展性,同时使用强化学习提升LLM性能。然而,当前强化学习算法仍有改进空间,奖励稀疏性是主要难点之一。