怎么提升向量数据库的召回准确率
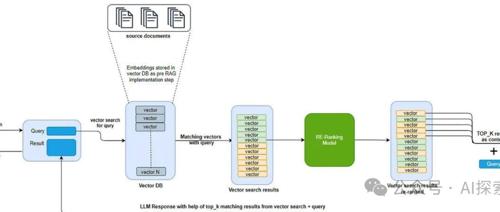
如何优化向量数据库的召回准确率是关键问题之一,主要从提高向量质量、改进索引结构、优化距离度量、改进查询策略、数据增强与处理、通过反馈机制优化以及多模态融合等方面着手解决。
如何优化向量数据库的召回准确率是关键问题之一,主要从提高向量质量、改进索引结构、优化距离度量、改进查询策略、数据增强与处理、通过反馈机制优化以及多模态融合等方面着手解决。

向量数据库通过向量化和相似度计算实现高效的数据检索。它主要应用于人工智能领域,并在推荐系统、图像识别等方面发挥作用。相比传统数据库,向量数据库擅长处理非结构化数据的语义相关性,其核心在于对不同模态数据进行向量化处理以及利用相似度计算算法来优化搜索性能和结果准确性。
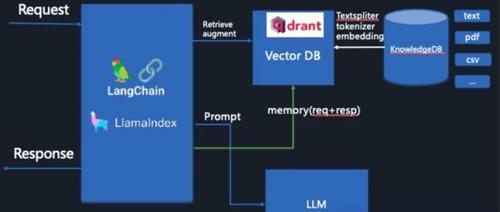
RAG系统中检索环节存在问题包括数据质量问题、向量化表示、检索方法与算法等多方面因素,文章提出优化建议以提升其性能,如使用高质量嵌入模型、定期更新数据库及调整相似度度量参数等。
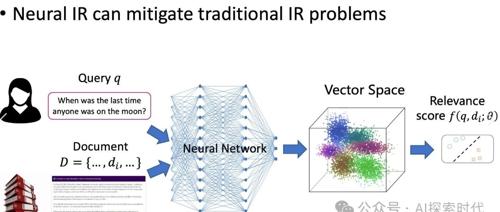
文本分块技术用于解决长文本处理中的上下文窗口限制问题。在大模型中采用类似阅读厚书的方法进行分块,使用chunk_overlap参数确保相关性。但在向量数据库中检索时,如何保证语义相关性的高效检索成为新挑战。
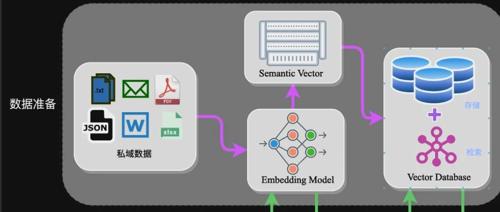
RAG技术涉及多个环节和多种技术,如向量数据库、embedding等。文章强调文本分块(chunk)在RAG中的重要性,分块将长文本切分成小段落便于管理和检索,提高模型处理效率及搜索准确性。
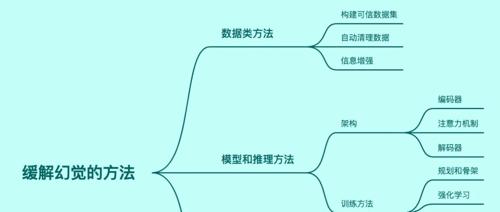
大模型技术已在部分企业应用场景中使用,但其不确定性(幻觉)问题成为限制因素,尤其在医疗、自动驾驶等对准确率要求高的领域。虽然解决幻觉问题是大势所趋,但也有人认为适度的“幻觉”有助于创新和错误带来的新发现。