怎么学习设计和训练一个大模型——也就是神经网络?
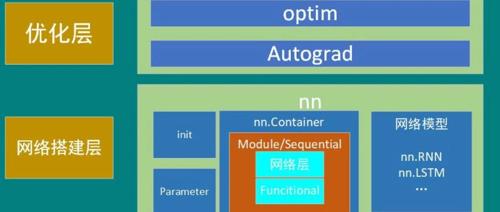
设计大模型需要先从技术点切入。建议初学者选择合适的工具(如PyTorch框架)和理论(如Transformer架构),专注于学习一种技术方向,并逐步理解其核心思想。
设计大模型需要先从技术点切入。建议初学者选择合适的工具(如PyTorch框架)和理论(如Transformer架构),专注于学习一种技术方向,并逐步理解其核心思想。
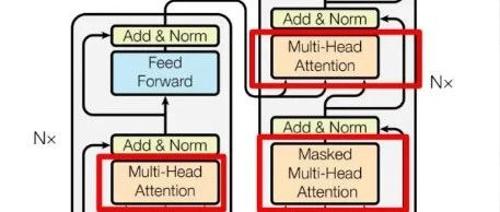
在文章中提到,通过PyTorch框架可以实现神经网络模型,并且PyTorch作为科学计算框架,主要用于进行数学运算。同时,文章也强调了Transformer架构的重要性及其与PyTorch的关系。总的来说,它说明了如何借助工具(如PyTorch)来构建和运行神经网络,并依靠理论(如Transformer)来指导其有效运作。
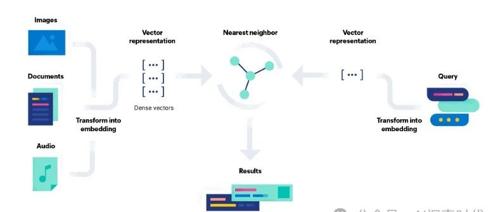
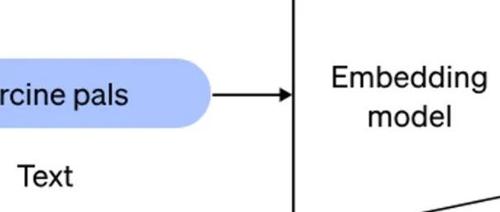
嵌入和向量化都是将数据转化为向量的过程,但嵌入更注重保留语义关系并能通过学习捕捉深层关系;向量化则侧重直接性,不需学习,通常基于规则或统计生成稀疏向量。二者可以结合使用以优化表示质量。
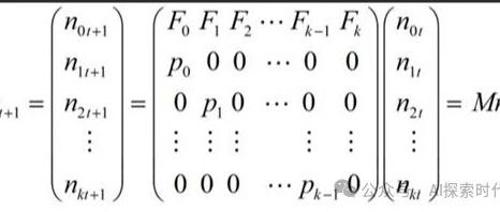
大模型的核心在于特征提取和重建。Transformer架构在NLP领域表现突出,而CNN则适用于图像处理。序列到序列(Seq2Seq)用于具有连续性内容的生成,如机器翻译、语音识别及视频处理等领域。CNN擅长处理不连续且独立的图像数据。
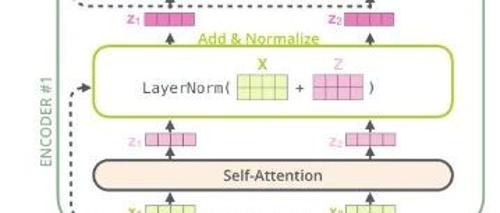
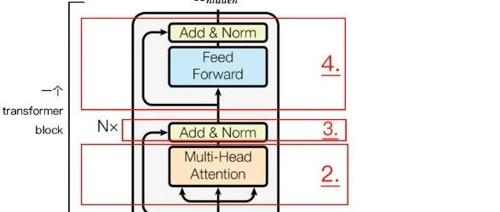
Transformer的编码器负责将人类可识别的数据转换为大模型可以处理的形式,并进行特征提取;解码器则用于重建模式,生成新的数据。其架构包括自注意力机制等多重数据处理步骤。
最近研究RAG后思考了嵌入与向量在大模型中的作用;嵌入解决数据向量化问题,向量则描述数据间关系;前者本质上是映射到高维矩阵中以捕捉语义关系,而后者则是数学概念中表示有方向和大小的量。