
 老刘说NLP
老刘说NLP

重磅!AI大模型又起飞了!!
随着AI技术的发展,程序员的职业命运正在发生改变。阿里云等多家公司已全面接入Agent体系,并要求员工具备大模型开发能力。未来企业更看重能使用AI技术重构业务流程的技术人才。AI相关岗位需求旺盛,薪资涨幅高达150%,年薪可达到70-100万。掌握AI大模型原理、应用技术和项目经验已成为就业新趋势。知学堂推出免费的「大模型应用开发实战训练营」课程,助力开发者快速转型为大模型应用开发工程师。
再看行业R1模型如何构建及减少推理大模型过度思考

今天是2025年3月23日,星期日。文章介绍了Fin-R1模型在金融领域的应用及其构建路线,包括数据处理和训练方法,并总结了减少推理大模型过度思考的技术方案。
21个RAG常用优化策略变体及notebook开源实操

本文介绍了21个RAG(Retrieval-Augmented Generation)的常用优化策略及对应的notebook实践,涵盖了从基础实现到高级应用的各种技术。包括Simple RAG、Semantic Chunking等,并提供了具体操作地址供读者参考和练习。

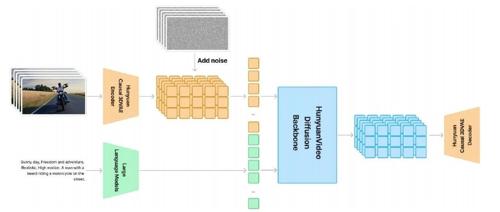



第一批抓住DeepSeek风口的研究生已经论文自由了
文章介绍了科研过程中的重要性,并强调了执行力和扎实工作的重要性。文中还推荐了《顶会顶刊12节论文写作课》,并提到了研梦非凡的论文辅导方案,指出好的idea是靠实干产生的。