ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍

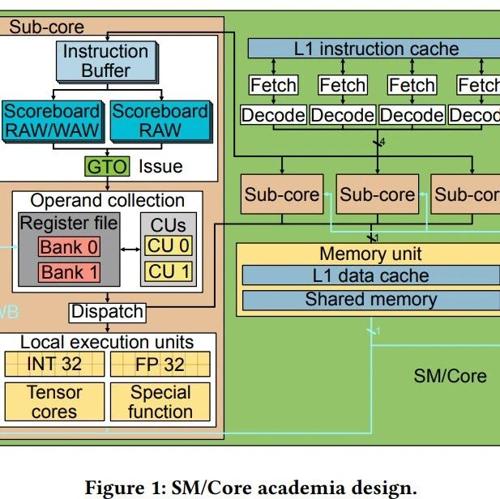
Mixture-of-Experts(MoE)架构尽管稀疏激活减少了计算量,但显存资源受限的端侧部署仍面临挑战。研究提出Mixture-of-Lookup-Experts(MoLE),通过将专家输入改为嵌入(token) token,利用查找表代替矩阵运算,有效降低推理开销,减少数千倍传输延迟。
Mixture-of-Experts(MoE)架构尽管稀疏激活减少了计算量,但显存资源受限的端侧部署仍面临挑战。研究提出Mixture-of-Lookup-Experts(MoLE),通过将专家输入改为嵌入(token) token,利用查找表代替矩阵运算,有效降低推理开销,减少数千倍传输延迟。

Google DeepMind的Gemini 2.5 Pro更新提升了编程能力和多模态推理功能,可构建Web应用、游戏和模拟程序,并根据自然图像生成代码。
RealtimeVoiceChat项目提供实时语音与AI对话功能,支持即时反馈、低延迟和多种模型引擎定制,可在GitHub上获取源码(https://github.com/KoljaB/RealtimeVoiceChat)。
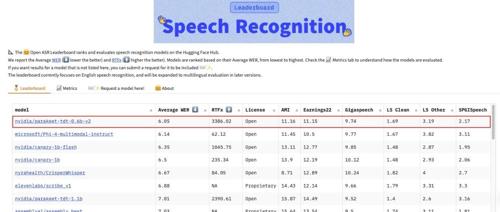
英伟达发布Parakeet TDT 0.6B V2开源语音识别模型,参数仅600M,平均词错误率(WER)6.05%,可在1秒内完成60分钟音频转录,支持英文,已入驻Hugging Face Open ASR榜单首位。

Hugging Face 新开源 nanoVLM 纯 PyTorch 实现,仅750行代码训练6小时即达35.3%准确率,支持免费 Google Colab 环境。体积222M参数量,模型高效易用,适合初学者快速入门视觉语言模型。

Google DeepMind发布的Gemini 2.5 Pro在LMArena多个AI竞技场全面领先,实现文本、视觉和Web开发领域的统治地位。该版本还显著提升了代码转换、编辑能力和复杂智能体的表现,并通过Google AI Studio和Vertex AI向开发者开放。