大模型RL不止数学代码!7B奖励模型搞定医学法律经济全学科, 不用思维链也能做题

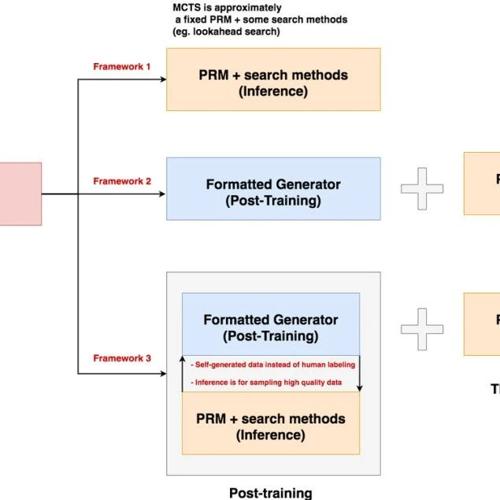
腾讯&苏州大学团队提出新框架RLVR,使用基于生成模型的软奖励提升大模型在医学、化学等多学科的能力。研究还开源了奖励模型和数据集,并指出未使用思维链推理方法仍需深入研究。
腾讯&苏州大学团队提出新框架RLVR,使用基于生成模型的软奖励提升大模型在医学、化学等多学科的能力。研究还开源了奖励模型和数据集,并指出未使用思维链推理方法仍需深入研究。

研究团队通过蒸馏技术从阿里通义Qwen2.5-32B-Instruct模型出发,结合Gemini 2.0 Flash Thinking实验版数据集训练出高性能推理模型s1-32B,在数学评测集中表现优异。

开源派掌门人Emad Mostaque批评DeepSeek依赖OpenAI蒸馏技术,并指出其R1-Zero模型通过生成数据自我提升。他质疑OpenAI数据影响,认为DeepSeek在思维链方面优于闭源竞争对手。这场争论反映了开源生态与闭源巨头的权力争夺和AI进化路径的分歧。

美国政府指控DeepSeek利用蒸馏技术从OpenAI模型中获取知识,OpenAI称其违反API使用条款,微软和OpenAI联合调查潜在的数据窃取行为。

国产AI模型DeepSeek-R1在Hugging Face开源社区迅速流行,下载量超70万次,引发美国海军和政府关注。其衍生模型数量每日增长30%,热度持续攀升。谷歌前CEO称这是全球AI发展的重要转折点,并推动Meta、Hugging Face等机构模仿DeepSeek的开发策略。

LLM模型通过纯强化学习提升推理能力,并提出无需监督数据的新方法。端侧模型性能提升主要依赖蒸馏而非强化学习,DeepSeek-R1-Zero展示了自我进化能力及语言一致性奖励的应用。