首个开源AI音频驱动的「多人对话」视频生成项目,还能通过提示词控制角色动作。

MultiTalk 是 MeiGen-AI 开发的音频驱动多人对话视频生成框架,支持单人/多人对话、卡通角色生成和唱歌场景模拟。具备480p/720p灵活输出能力,最长15秒长视频生成能力,并引入优化技术提高性能。
MultiTalk 是 MeiGen-AI 开发的音频驱动多人对话视频生成框架,支持单人/多人对话、卡通角色生成和唱歌场景模拟。具备480p/720p灵活输出能力,最长15秒长视频生成能力,并引入优化技术提高性能。

Midjourney发布首款视频生成模型V1,支持手动或自动生成动作提示词,可生成最长20秒的流畅视频。但目前功能仍有限,无法生成音频和进行编辑。
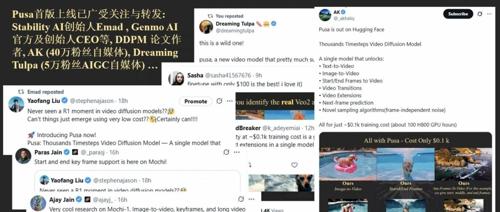
FVDM & Pusa 提出了一种新的视频扩散模型 (FVDM),通过引入向量化时间步变量 (VTV) 解决了传统视频生成的局限性。Pusa 项目利用非破坏性微调方法将预训练模型成本降低了数倍,展示了低成本、高灵活视频生成的新时代。

普林斯顿大学和Meta联合推出的新框架LinGen,以线性复杂度的MATE模块替代传统自注意力,使单张GPU在分钟级长度下生成高质量视频成为可能。

本文介绍了一次视频生成的教程,探讨了其作为世界模型的强大潜力,涵盖学术界和产业界的顶尖研究者分享,涉及生成建模、3D理解、强化学习与物理推理等方向。

昆仑万维开源的Matrix-Game项目作为首个17B参数交互式世界基础模型,通过两阶段训练策略生成高保真、可控视频,涵盖虚拟游戏、影视制作及元宇宙领域。