
鲁棒性


为什么用错奖励,模型也能提分?新研究:模型学的不是新知识,是思维

本文研究了语言模型对强化学习中奖励噪声的鲁棒性,即使翻转大部分奖励也能保持高下游任务表现。作者提出了思考模式奖励机制,并展示了其在数学和AI帮助性回复生成任务中的有效性。


入选CVPR 2025,哈工大团队提出分层蒸馏多示例学习框架HDMIL,快速处理千兆像素病理全切片图像

授和张永兵教授团队,创新提出一种分层蒸馏多示例学习框架
HDMIL,旨在快速识别不相关的 patch

Token刺客来袭!AgentPrune一键屏蔽废话智能体,成本暴降60%性能翻盘

由同济大学、香港中文大学等机构提出的新技术AgentPrune,通过多智能体剪枝技术解决基于大模型的多智能体系统中的通信冗余问题。该技术能大幅降低通信开销,提升系统的鲁棒性和任务完成效率。
ICLR25|突破传统微调的知识编辑新范式!北京通用人工智能研究院、中科大、北大提出In Context Editing!
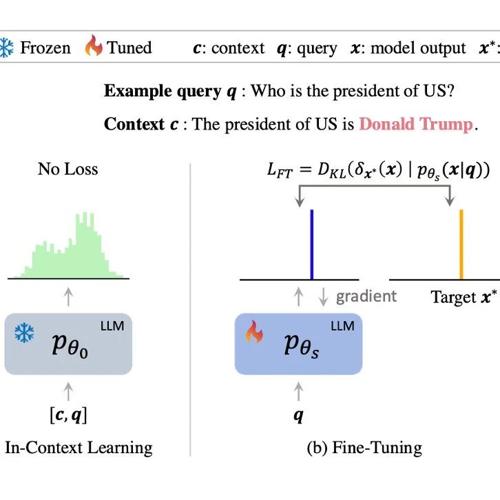
大、北大提出
In Context Editing
,这是一种突破传统微调,从自诱导分布中学习知识的
