
强化学习

SFT并非必需!推理模型仅靠RL就能获得长思维链能力,清华CMU团队破解黑盒

研究团队通过对比SFT和RL两种方法发现,长CoT的生成需要大量的计算资源。他们提出了四个关键发现:SFT并非必需但能简化训练并提高效率;推理能力随着训练计算增加而出现,但并非总是如此;可验证奖励函数对增长CoT至关重要;基模型中的错误修正等技能需要通过RL有效地激励。
喝点VC|光速美国:Deepseek仍未能全面赶超最强基础模型,迈向下一个前沿需要大量资本

DeepSeek仅用600万美元训练出强大AI模型引起广泛关注,但其真正的价值在于推动技术发展。文章指出,美国的大型AI实验室应将AI的安全研究和开发作为优先事项,强调迈向AGI(通用人工智能)才是关键目标。

DeepSeek GRPO 技术揭秘:Unsloth 助力 7GB 显存体验“顿悟时刻”

DeepSeek R1 模型利用 GRPO 算法实现自主学习能力,仅需 7GB 显存即可训练出具备推理能力的模型,大幅降低训练门槛和成本。
从扭秧歌到单脚跳,HugWBC让人形机器人运动天赋觉醒了

AIxiv专栏介绍及其新成果HugWBC控制器,支持机器人同时掌握多种步态及精细调整行为指令,提高运动控制能力。该研究成果在模拟环境中训练,并通过评估验证其有效性。
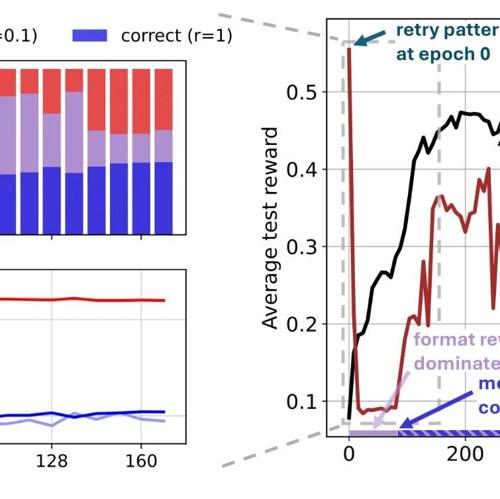
R1-Computer-Use:将Deepseek R1的强化学习技术应用于计算机使用场景
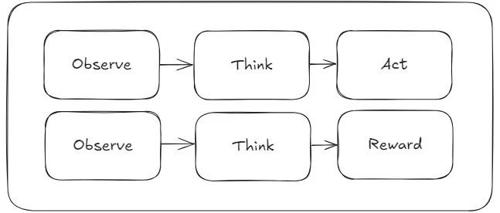
R1-Computer-Use利用Deepseek R1的强化学习技术优化计算机使用场景中的AI行为,支持文件操作、命令行交互等多种任务。

