
通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview

UC伯克利团队通过RL微调改进Deepseek-R1-Distilled-Qwen-1.5B,使其在AIME基准上Pass@1准确率高达43.1%,参数量仅为1.5B且超越OpenAI o1-preview。
UC伯克利团队通过RL微调改进Deepseek-R1-Distilled-Qwen-1.5B,使其在AIME基准上Pass@1准确率高达43.1%,参数量仅为1.5B且超越OpenAI o1-preview。

本所发表的看法再一次受到关注与热议。2 月 9 日,谷歌 DeepMind 首席执行官 Demis

2025年开年,国产大模型DeepSeek凭借低成本、高性能和全开源特性震撼全球。从数学竞赛到汽车智能座舱,DeepSeek重塑了多个行业应用,并在技术突破和实际落地方面展现了巨大潜力。
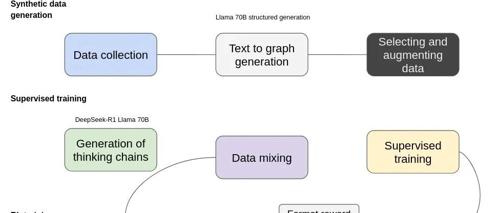
该项目基于Hugging Face Open-R1和trl构建,并重现了DeepSeek R1训练方案。通过合成数据生成、监督训练和强化学习(使用GRPO策略优化)等步骤,旨在提高模型进行文本到图信息提取的能力。

Unsloth AI 提供了 GRPO 训练算法,使用户能够在仅 7GB VRAM 上重现 DeepSeek R1-Zero 的‘顿悟时刻’,相比传统方法减少约80%的 VRAM 使用量。




