
强化学习之父:LLM主导只是暂时,扩展计算才是正解

新晋图灵奖得主Richard Sutton预测大模型主导是暂时的,未来五年甚至十年内AI和强化学习将转向通过Agent与世界的第一人称交互获取‘体验数据’的学习。他强调AI需要新的数据来源,并且要随着增强而改进。他认为真正的突破还是来自规模计算。
新晋图灵奖得主Richard Sutton预测大模型主导是暂时的,未来五年甚至十年内AI和强化学习将转向通过Agent与世界的第一人称交互获取‘体验数据’的学习。他强调AI需要新的数据来源,并且要随着增强而改进。他认为真正的突破还是来自规模计算。

西湖大学研究团队提出SLOT方法,在推理时通过优化delta参数向量调整输出词汇概率分布,显著提升语言模型在复杂指令上的表现。
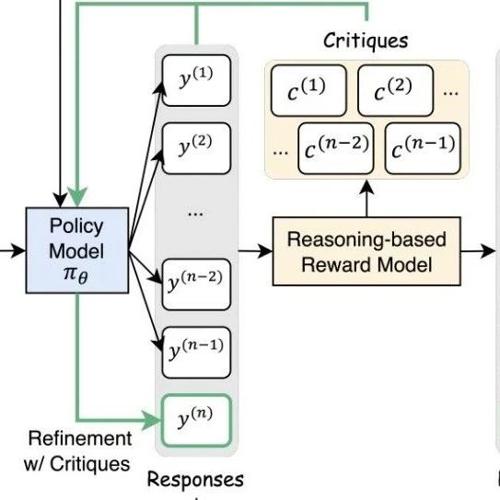
MLNLP社区是国内外知名的人工智能和技术交流平台,旨在促进机器学习和自然语言处理领域内的学术与产业界的交流合作。近日发布的论文探讨了改进语言模型推理能力的方法,并提出了一种名为Critique-GRPO的技术方案。

本文研究了语言模型对强化学习中奖励噪声的鲁棒性,即使翻转大部分奖励也能保持高下游任务表现。作者提出了思考模式奖励机制,并展示了其在数学和AI帮助性回复生成任务中的有效性。

特斯拉员工Milan Kovac因个人原因离职,Optimus项目负责人职务暂由Ashok Elluswamy接任。马斯克和特斯拉面临新挑战,近期股价波动加剧了公司的经营压力。

SophiaVL-R1 是一项基于类 R1 强化学习训练框架的新模型,它不仅奖励结果的准确性,还考虑了推理过程的质量。通过引入思考奖励机制和 Trust-GRPO 训练算法,SophiaVL-R1 提升了模型的推理质量和泛化能力,在多模态数学和通用测试数据集上表现优于大型模型。

今天是2025年6月6日,星期五,北京晴。文章回顾了大模型相关技术进展,包括针对性学习、推理数据收集、多模态应用及强化学习评估偏差等内容。关键点在于明确问题并针对性学习,学会提问和理论与实践结合,以提升大模型性能。


