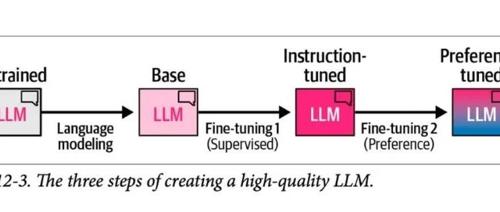
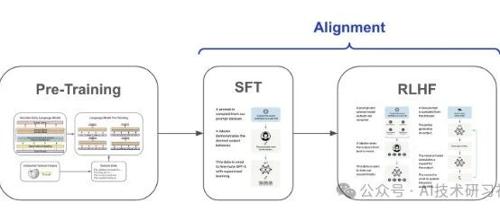
监督微调

SFT并非必需!推理模型仅靠RL就能获得长思维链能力,清华CMU团队破解黑盒

研究团队通过对比SFT和RL两种方法发现,长CoT的生成需要大量的计算资源。他们提出了四个关键发现:SFT并非必需但能简化训练并提高效率;推理能力随着训练计算增加而出现,但并非总是如此;可验证奖励函数对增长CoT至关重要;基模型中的错误修正等技能需要通过RL有效地激励。
李飞飞团队50美元训练出DeepSeek R1?

文章介绍了通过16块H100 GPU在26分钟内训练出低成本语言模型S1K的方法,该模型与OpenAI的o1系列和DeepSeek R1系列性能相当。但实际研究发现,论文核心是基于开源Qwen2.5-32B模型,进行小数据集监督微调,并非直接复制了DeepSeek R1。


最新全球模型榜单:阿里 Qwen2.5-Max超DeepSeek V3

阿里最新大语言模型Qwen2.5-Max在Chatbot Arena榜单上排名第7,领先于DeepSeek V3等顶级模型。其在数学和编程方面排名第一,在处理复杂任务的硬提示方面排名第二。