
注意力机制





清华SageAttention3,FP4量化5倍加速!且首次支持8比特训练

清华大学陈键飞团队提出SageAttention3,实现了5倍于FlashAttention的推理加速。此模型在多种视频和图像生成等大模型上保持了端到端的精度表现,并首次提出了可训练的8比特注意力用于大模型的训练加速。
OpenAI联合创始人Ilya精选的AI论文清单
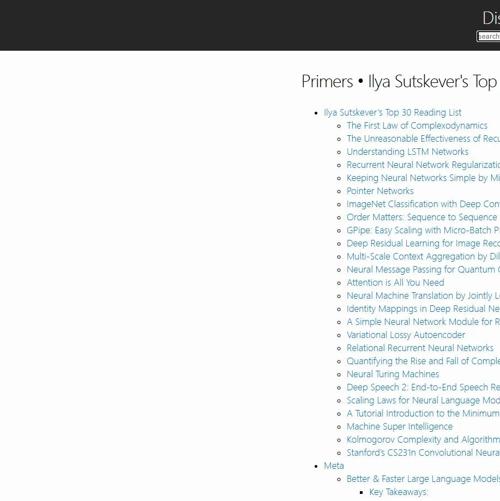
OpenAI联合创始人Ilya精选的AI论文清单包含30篇基础、优化和应用类论文,涵盖RNN/LSTM、CNN、Transformer等技术,内容涉及正则化、生成模型、对齐等多个领域。
无坐标时代来临!微软开源革命性GUI定位神器,注意力机制+多区域预测,适配任意屏幕!
微软开源GUI-Actor无坐标视觉定位工具,通过注意力机制直接识别目标区域,支持网页、桌面和移动端UI,性能媲美甚至超越传统方法。

