弄明白智能体的运作流程,才能知道智能体目前存在那些问题,以及应该怎么解决
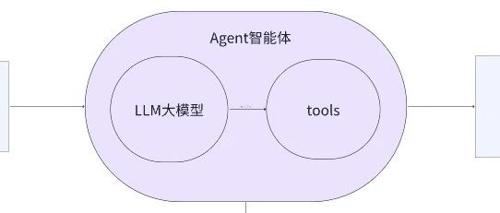
文章介绍了智能体的复杂性和不可控性,并提出了多智能体架构来解决这些问题。但同时也指出多智能体之间的通讯问题以及业务流程中可能需要其它业务处理或人工参与的情况。
文章介绍了智能体的复杂性和不可控性,并提出了多智能体架构来解决这些问题。但同时也指出多智能体之间的通讯问题以及业务流程中可能需要其它业务处理或人工参与的情况。

大模型在数学推理和解答题上表现参差不齐,多数模型在图像识别方面仍存在问题。总体来看,大模型在复杂推理、严谨论证及多步骤计算能力上有较大提升空间。

硅基流动宣布完成数亿元A轮融资,阿里云领投。该公司专注于AI Infra领域,致力于破解AI算力问题,并推出一站式异构算力纳管平台及大模型云服务平台SiliconCloud。