
RAG技术

我们需要学会对大模型祛魅,大模型没有大家想象中的那么复杂
大模型看似复杂,但通过工具思想即可轻松驾驭。文章指出大模型其实是一个模仿人脑神经网络的数学模型,主要进行理解与生成两个步骤。尽管存在多种任务类型的大模型,基本遵循输入理解和结果生成的过程。技术开发者只需调用几个接口和编写提示词便能实现应用需求。
20家单位参与,《面向人工智能的数据标注合规指南》征集中

阿里开源的Qwen2.5系列训练数据规模达到18万亿token,远超其他模型。然而,这带来幻象问题的风险促使RAG技术及企业专有知识数据的价值提升,强调了数据采集、标注和管理的重要性。政策层面,《关于促进数据标注产业高质量发展的实施意见》发布,进一步推动数据标注产业发展。《标准》旨在解决数据标注中的合规问题,提高行业规范化发展水平。
RAG 正在重塑未来:最新 11 种新型 RAG 类型一次看懂!
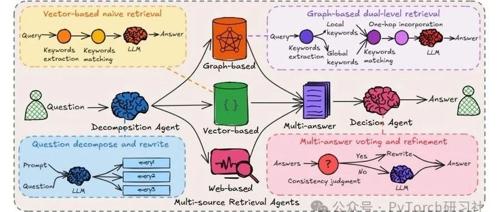
多种最新的RAG类型包括协同式(CoRAG)、推理控制(ReaRAG)、多模态和多智能体(HM-RAG)等,展示了RAG技术在复杂任务中的应用和发展方向,帮助LLM提升推理能力、适应性和准确性。
破解合规难题,AI高质量数据集建设正当时
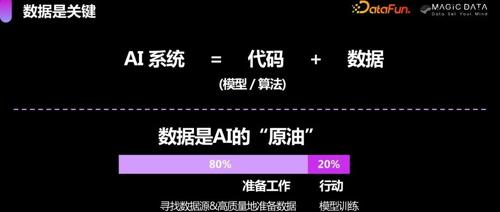
阿里开源的Qwen2.5系列训练数据规模达18万亿 token,推动AI大模型发展。但大规模训练带来幻象问题,RAG技术及工业场景应用以数据为中心成为趋势。国家和行业正积极推进数据标注产业发展规范,提升数据标注行业的合规能力。
大模型数据预处理——关于复杂文档在大模型应用中的解决方案

复杂文档处理是AI的基础但门槛高。常见文本类文档如Word/PDF格式复杂难处理,影响RAG应用效果。为提高效率,可将多种文档统一转为HTML或Markdown格式,并进行进一步处理。
关于打造高质量RAG系统的问题记录
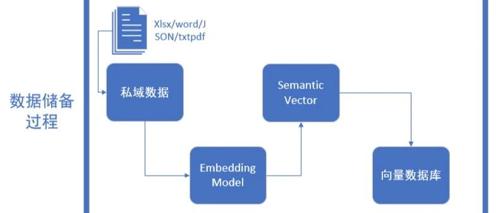
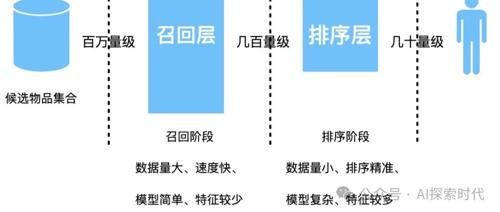
关于RAG在实际场景中的应用,重点讨论了文档处理和高效检索的问题。文档处理涉及多样化和复杂的格式,需要拆分和识别文本、图片和图表等不同内容类型。高效的检索则需利用多种匹配方式(精确字符匹配与语义匹配),通过多路召回策略综合考虑多个维度的数据来优化结果。
赢麻了!全体程序员彻底狂欢吧!这个好消息来得太及时!

阿里云等企业全面接入AI技术,要求员工掌握大模型开发能力。传统开发框架面临淘汰,AI相关岗位需求暴增且薪资上涨。知乎知学堂推出免费课程,涵盖大模型原理、应用技术和实战经验,助力学员从开发者转型为大模型应用开发工程师。