
智谱新版VLM开源模型 GLM-4.1V-9B-Thinking
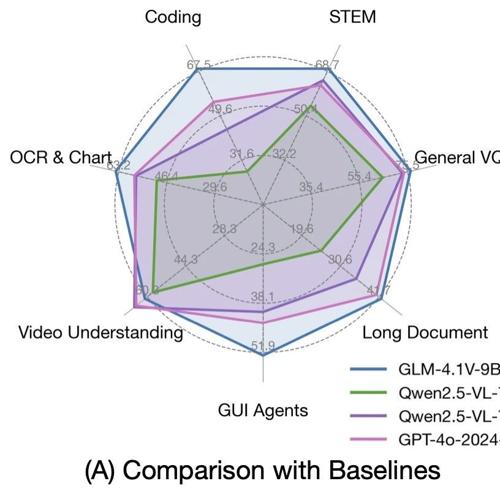
基于GLM-4.1V-9B-Thinking模型,引入强化学习技术提升视觉语言模型能力,在18个任务中与8倍参数量的Qwen-2.5-VL-72B相当或超越
基于GLM-4.1V-9B-Thinking模型,引入强化学习技术提升视觉语言模型能力,在18个任务中与8倍参数量的Qwen-2.5-VL-72B相当或超越

基于强化学习训练的视觉语言模型成功在开放GUI环境中进行了自我探索,提升了智能体的交互能力。该研究展示了如何结合探索奖励、世界模型和GRPO强化学习来增强智能体的探索效率,并通过经验流蒸馏技术进一步提升了其自主性。

VRAG-RL 是一种基于强化学习的视觉检索增强生成方法,通过引入多模态智能体训练,实现了视觉语言模型在检索、推理和理解复杂视觉信息方面的显著提升。

香港中文大学与新加坡国立大学的研究者提出了一种名为TON的新颖选择性推理框架,让视觉语言模型可以自主判断是否需要显式推理。该方法显著减少了生成的思考链长度,提高了模型推理过程的效率,并且在不牺牲准确率的前提下提升了响应多样性。
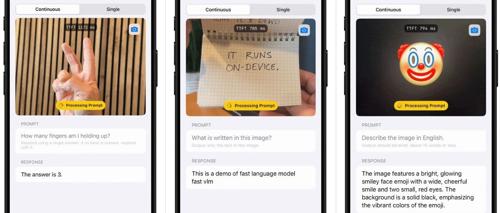
苹果开发的高效视觉语言模型FastVLM采用新型混合视觉编码器FastViTHD,实现高分辨率图像处理速度提升3.2倍的同时保持精度。
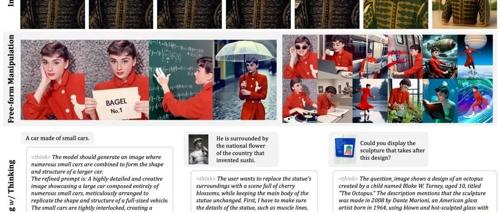
BAGEL 是一个开源多模态基础模型,拥有70亿活跃参数,在标准多模态理解排行榜上超越了当前顶尖开源模型,并展示了高级编辑能力及扩展至世界建模的能力。
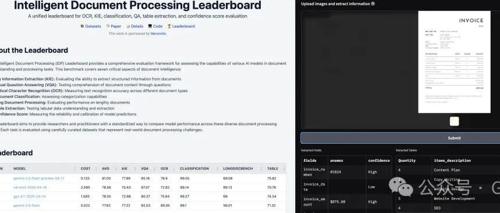
docext是无需OCR的新工具,用于从发票和护照等文档图像中提取结构化信息。它利用视觉语言模型准确识别并提取数据和表格信息。智能文档处理排行榜追踪和评估其在关键任务中的表现。


