关于人工智能应用场景中前期数据处理的业务场景和技术分析——包括结构化数据和非结构化数据
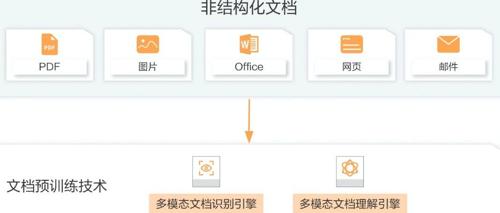
文档处理在人工智能领域中至关重要,涉及复杂的业务场景和技术实现。文章讨论了不同类型文档的处理方法及其技术方案,指出非结构化数据是最具挑战性的类型之一,需要采用多模态模型和特定技术来简化处理过程。
文档处理在人工智能领域中至关重要,涉及复杂的业务场景和技术实现。文章讨论了不同类型文档的处理方法及其技术方案,指出非结构化数据是最具挑战性的类型之一,需要采用多模态模型和特定技术来简化处理过程。
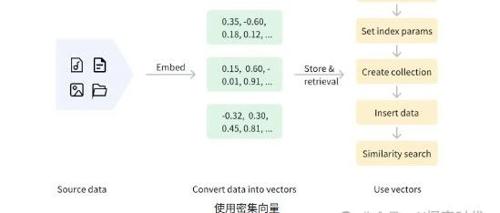
不同的向量类型可能导致相似度检索策略不同。Milvus支持稠密和稀疏向量,以及混合搜索技术。稠密向量用于语义检索,稀疏向量用于精确关键词匹配,混合搜索适用于复杂场景。
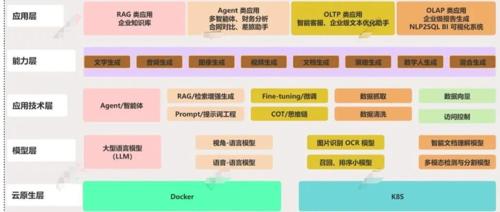
大模型的能力由多个因素决定,包括神经网络技术的发展、训练数据的选择与质量、模型结构的固有缺陷、以及微调等。提升大模型潜力的方法则涉及模型架构改进、算法选择、数据质量优化等多个方面。提示词工程是一种常用手段,通过调整提示词激发大模型潜力,促进其在特定任务上的表现。
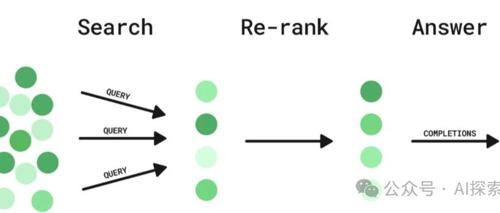
在RAG系统中,Embedding和Rerank模型是核心组成部分。前者将文本转化为低维向量以捕捉语义信息;后者则用于对候选结果进行重排序,提升其相关性。
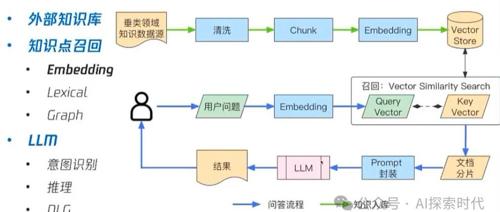
最近在RAG项目中使用milvus向量数据库时遇到问题,文档格式复杂导致相似度较低,提出通过重排序、多路召回等方式解决数据干扰因素变多的问题。