预训练无了?手撕LLM+O1 强化学习后训练指南!!

原创超长文知识分享,手撕o1推理、RL、PPO等课程内容已帮助多名同学成功上岸LLM赛道。课程包含多卡训练实操、Pytorch实现代码等,适合零基础到进阶学员学习。
原创超长文知识分享,手撕o1推理、RL、PPO等课程内容已帮助多名同学成功上岸LLM赛道。课程包含多卡训练实操、Pytorch实现代码等,适合零基础到进阶学员学习。

本公众号介绍Omniparser框架及其在文本识别、关键信息提取和表格识别中的应用。通过两阶段、三种序列化方式有效压缩原始长序列,并使用空间和字符导向的窗口提示增强理解能力。

近期微软开源了MarkItDown,一款将PDF、PPT、Word等文件转换为Markdown的实用程序,支持多种格式,并提供Python基本用法和使用大型语言模型进行图像描述示例。

本公众号介绍的Verify-and-Edit (VE)框架通过后期编辑推理链提高预测的事实性。它包含五个步骤:一致性检查、生成验证问题、外部知识检索、修改理由和生成新预测。VE提高了20%的精准度。

文章介绍了沃恩智慧为科研者提供的学术背景提升服务,包括20年经验的导师一对一指导、零基础直达SCI/CCF论文发表等,旨在帮助学生顺利毕业、保送升学及留学申博。同时提供大模型支持和免费课程优惠。

Qwen团队成员认为预训练在智能体、合成数据和推理方面仍具有重要作用,并且需要更多时间进行优化以覆盖整个互联网知识。同时,强调了预训练模型质量对合成数据和后训练的影响以及训练大型模型的挑战。
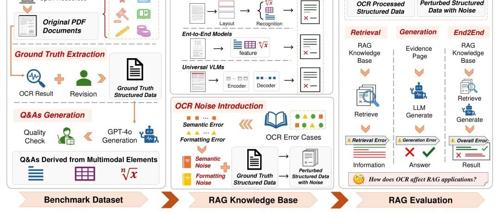
在RAG系统中,基于OCR的非结构化PDF文档抽取导致知识库中的语义噪声和格式噪声问题,影响RAG系统的性能。OHRBench评估了当前OCR解决方案,并推荐使用Marker实现最佳检索性能,但所有解决方案仍存在性能下降。

OpenAI 联合创始人 Ilya Sutskever 在 NeurIPS 2024 上演讲,认为数据资源接近极限且预训练模型即将终结,未来 AI 将更依赖于自主智能体和合成数据,并可能达到超级智能状态。
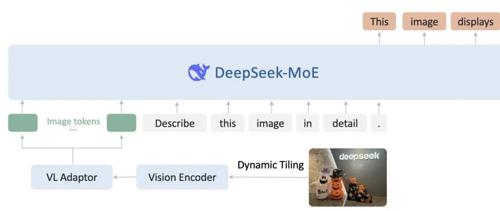
DeepSeek-VL2是先进的大型混合专家视觉-语言模型系列,显著改进了其前身DeepSeek-VL,在包括视觉问题回答、光学字符识别、文档/表格/图表理解以及视觉定位等多种任务上表现出卓越的能力。