
NeurIPS 2024|收敛速度最高8倍,准确率提升超30%!华科发布MoE Jetpack框架
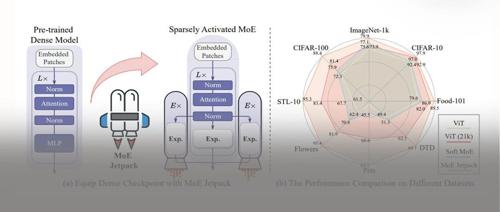
华中科技大学提出MoE Jetpack框架,利用密集模型预训练权重微调为混合专家模型,显著提升精度和收敛速度。
华中科技大学提出MoE Jetpack框架,利用密集模型预训练权重微调为混合专家模型,显著提升精度和收敛速度。

↑ 点击
蓝字
关注极市平台
作者丨AI生成未来
来源丨AI生成未来
编辑丨极市平台
极市导读
模型
本文介绍了如何使用TensorRT加速通过PyTorch Eager Mode量化接口生成的量化模型,包括量化步骤、修复ONNX模型图以及构建和验证TensorRT引擎等内容。

近日,DeepMind团队与马里兰大学研究人员在结合水印技术和投机采样方面取得进展。研究揭示了水印强度和采样效率之间的不可行定理,并提出了两种方法来平衡两者。研究表明,在保持检测效率或速度上存在权衡关系,未来需要设计新算法以应对这一挑战。





