
阿里开源长文本深度思考模型!渐进式强化学习破解长文本训练难题,登HuggingFace热榜
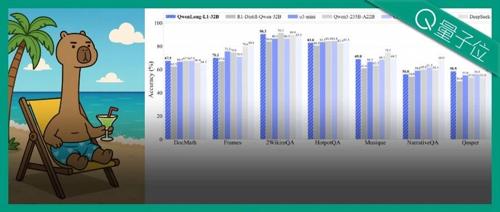
阿里开源的QwenLong-L1模型在HuggingFace今日热门论文第二,其32B参数版本性能优秀。对比基础模型,QwenLong-L1通过回溯和验证机制成功处理了长文本推理中的干扰信息问题,准确计算了金融文档中涉及优先票据发行成本与第一年利息支出合并的总资本成本。
阿里开源的QwenLong-L1模型在HuggingFace今日热门论文第二,其32B参数版本性能优秀。对比基础模型,QwenLong-L1通过回溯和验证机制成功处理了长文本推理中的干扰信息问题,准确计算了金融文档中涉及优先票据发行成本与第一年利息支出合并的总资本成本。

上海交大等团队推出Visual-ARFT项目,专为视觉语言模型设计多模态智能体训练方法,实现图像理解与操作能力。项目开源并测试表明其在复杂任务中超越GPT-4o,展现强大工具调用和推理能力。

CVPR 2025 论文分享会将在北京举办,主题包括多模态和视频生成。邀请顶级专家、论文作者参加Keynote演讲和圆桌对话,同时发布部分论文的摘要。






