
工业异常检测新突破,复旦等多模态融合监测入选CVPR 2025

复旦大学、荣旗工业科技、腾讯优图实验室等机构联合发布了高精度多模态数据集Real-IAD D³,并提出了一种基于此数据集的创新多模态融合检测方法,提升了工业异常检测性能。
复旦大学、荣旗工业科技、腾讯优图实验室等机构联合发布了高精度多模态数据集Real-IAD D³,并提出了一种基于此数据集的创新多模态融合检测方法,提升了工业异常检测性能。

东南大学联合多所研究机构提出了KRIS-Bench,一个评估图像编辑模型知识结构的基准。该基准从事实性、概念性和程序性知识三个层面测试编辑能力,并包含1267对图像指令样本,覆盖初级到高级任务难度。

MASLab 提供了一个统一、全面的多智能体系统代码库,涵盖多种方法和评测基准。它支持跨领域实验,并提出MASLab-ReAct方法,用于评估大模型在多任务环境下的性能。
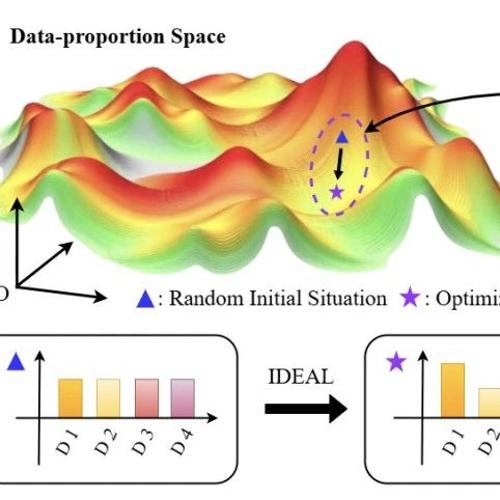
MLNLP社区发布了一项创新方法IDEAL,用于解决大型语言模型(LLM)在多任务场景下可能出现的偏科现象。通过调整监督微调(SFT)训练集组成,研究团队发现优化后的模型在多种领域上的综合性能显著提升。

Video-Bench通过链式查询和少样本评分技术,实现了对视频生成质量的高效评估。该框架能够全面覆盖视频生成的多个维度,并在视频-条件一致性、视频质量等方面显著优于现有方法。

本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。

上海交通大学及上海AI Lab联合团队提出IDEAL方法,通过调整SFT训练集的组成来提升LLM在多种领域上的综合性能。研究发现增加训练数据数量并不一定提高模型整体表现,反而可能导致“偏科”。

研究团队发布了一项包含1000个高质量问题的音频理解评估基准MMAR,测试了30款模型的表现。结果表明大多数开源模型在面对复杂音频推理任务时表现不佳,而闭源模型Gemini 2.0 Flash则表现出色。该基准展示了当前AI在音频理解方面的不足,并强调了数据和算法创新的重要性。

智源研究院联合上海交通大学发布新一代超长视频理解模型Video-XL-2,单张显卡即可高效处理万帧视频,编码2048帧仅需12秒。该模型在多个维度表现优异,并向社区开放权重,有望在影视分析、异常检测等场景中广泛应用。
