
ICML 2025 如何在合成文本数据时避免模型崩溃?

生成式人工智能技术下合成数据成为大模型训练的重要组成部分。然而,研究团队提出了一种创新方法Token-Level Editing,以避免模型崩溃问题,通过微编辑而非纯生成来构建稳定、泛化性强的半合成数据。
生成式人工智能技术下合成数据成为大模型训练的重要组成部分。然而,研究团队提出了一种创新方法Token-Level Editing,以避免模型崩溃问题,通过微编辑而非纯生成来构建稳定、泛化性强的半合成数据。

上海交通大学、北京智源研究院和特伦托大学的研究团队推出了一种新的超长视频理解大模型Video-XL-Pro,该模型通过创新的重构式令牌压缩技术实现了近一万帧视频的单卡处理,并在多个基准测试中超越了此前发布的大型模型。

上海交通大学等团队推出Video-XL-Pro模型,实现近一万帧视频的单卡处理,超过Meta发布的7B模型Apollo-7B。采用重构性token压缩技术显著提升了视频理解效率和质量,并在多个长视频评测基准上超越了同参数量的开源模型。
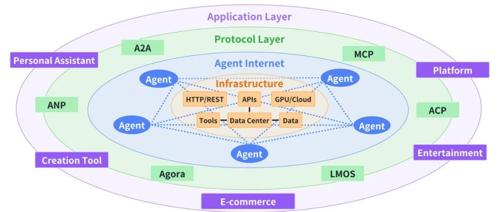
上海交通大学团队发布论文《A Survey of AI Agent Protocols》,提出二维分类体系和七大维度评估框架,旨在解决智能体间协议碎片化问题。该研究通过真实案例分析展示了不同协议在旅行规划中的应用差异,并对未来AI智能体协议的发展进行了展望。

ISCA Fellow 2025揭晓,8位华人学者入选。包括思必驰俞凯、中国台湾大学李宏毅及A*STAR Nancy Chen等多位专家。
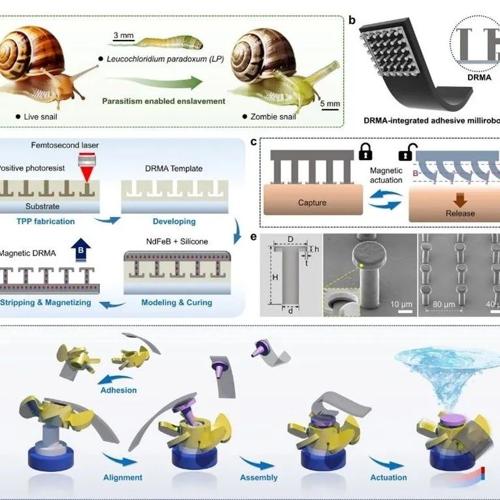
上海交通大学团队开发出一种两栖粘附磁驱微型机器人,能够在空气和水中自如切换并操控多种目标。该研究发表于《Advanced Materials》期刊,提出利用双折返微阵列结构实现可靠粘附力,并展示其在干湿环境中的应用优势及多模态运动控制能力。



