
5%参数比肩DeepSeek满血R1!北大“小”模型靠分合蒸馏,打破推理成本下限

北京大学杨仝教授团队发布FairyR1-32B模型,该模型基于DeepSeek-R1-Distill-Qwen-32B基座,通过微调与模型合并技术,在参数量大幅减少的情况下实现了数学和代码任务上的优异性能。
北京大学杨仝教授团队发布FairyR1-32B模型,该模型基于DeepSeek-R1-Distill-Qwen-32B基座,通过微调与模型合并技术,在参数量大幅减少的情况下实现了数学和代码任务上的优异性能。

2025年5月26日,Datawhale与字节跳动扣子空间联合主办‘AI+X高校行’首场活动在北大启动,聚焦Agent技术普及,覆盖百所高校,提供从理论到实践的学习体验。
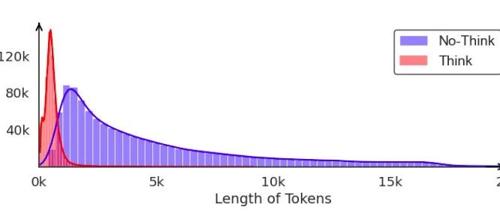
微软研究院与北大提出的大规模混合推理模型LHRMs能够在用户查询时自适应地决定是否进行思考,实现更快、更自然的日常交互,并在推理和通用能力方面超越现有模型的同时显著提高了效率。
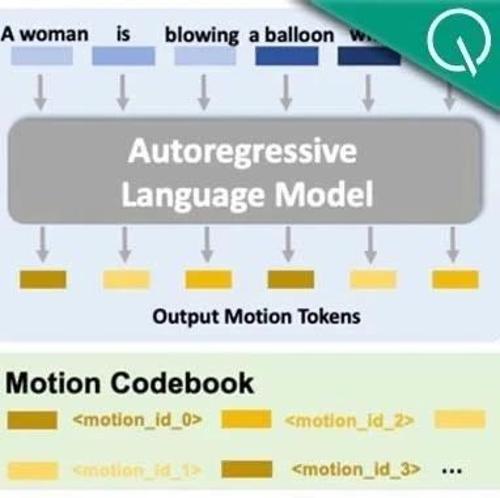
北大卢宗青团队在通用人形机器人动作生成领域取得突破,提出Being-M0框架和MotionLib数据集,实现了大规模且多样化的复杂人类动作生成,并验证了大数据+大模型的可行性。
该研究由通用人工智能研究院与北京大学合作开发了一种名为MCU的生成式开放世界平台,用于评估通用智能体在复杂环境中的能力。MCU支持无限多样化的任务配置和环境变量,旨在全面测试智能体的真实能力和泛化水平,并通过高效的工具简化评测流程。论文详细介绍了MCU的设计及其功能突破。

Mixture-of-Experts(MoE)架构尽管稀疏激活减少了计算量,但显存资源受限的端侧部署仍面临挑战。研究提出Mixture-of-Lookup-Experts(MoLE),通过将专家输入改为嵌入(token) token,利用查找表代替矩阵运算,有效降低推理开销,减少数千倍传输延迟。

2025年北京大学校友科技创新论坛在北京大学秋林报告厅举办,汇聚全球顶尖科学家、企业家和创业者。论坛聚焦前沿技术趋势与产业转化路径,促进产学研合作,推动科技创新与发展。

本文提出了一种名为 DiffFNO 的方法,利用神经算子和扩散模型解决超分辨率问题。它通过加权傅里叶神经算子、门控融合机制和自适应 ODE 求解器实现了高精度和快速推理,超越了现有技术。
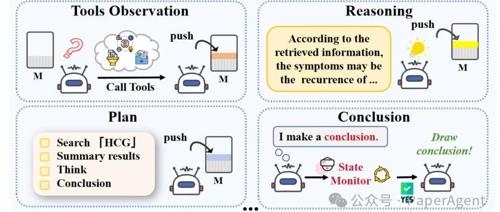
Agentic RAG-R1 是由北京大学研发的一项开源研究项目,通过引入强化学习策略(GRPO),构建了一个可自我规划、检索、推理与总结的智能体式 RAG 系统,显著提升了语言模型的自主性和效率。
