
微软&清北RPT:强化学习的风又吹到了预训练!
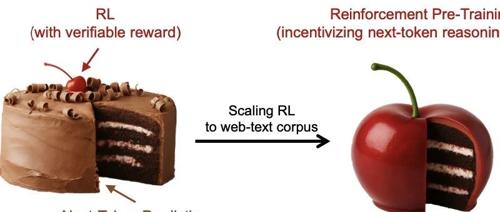
微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。
微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。

北京大学联合智元机器人团队提出CheckManual评测框架,专注于研究基于说明书的家电操作。该框架包含1107份不同内容的家电说明书,涵盖2211个可操作部位和1464个操作任务。通过OCR、多模态大模型解析说明文字及视觉信息,提出ManualPlan模型进行详细的操作规划,并实现与家用电器的真实交互。

VidText 提出了一套全面的视频文本理解基准,覆盖 27 个真实场景和多种语言。它包含从视觉感知到跨模态推理的多个任务,评估模型在不同粒度上的表现,并揭示了影响性能的关键因素。

近日,微软研究院与北京大学联合发布的新框架Next-Frame Diffusion(NFD)实现了每秒超过30帧的视频生成速度,并保持高质量画面。相比现有自回归视频生成模型,NFD采用帧内双向注意力和帧间因果依赖机制建模视频,并通过多步迭代和并行采样提高效率。

微软亚洲研究院联合清华大学、北京大学提出RPT预训练范式,将强化学习深度融入预训练阶段,通过生成思维链推理序列和使用前缀匹配奖励来提升模型预测准确度。

2025 北京智源大会召开,银河通用机器人Galbot亮相主论坛并展示端到端具身大模型GroceryVLA技术能力。此次发布展示了其在零售行业的真实商业落地能力,并发布了全开源人形机器人遥操作系统OpenWBT。

北京大学提出VGP方法,通过语义低秩分解增强图结构图像模型的参数高效迁移能力,在多种下游任务中实现媲美全量微调的性能。
MLNLP社区致力于促进国内外机器学习与自然语言处理的学术交流。该社区涵盖了985高校及部分双非院校,如华为目标院校名单中包括多所顶尖高校。社区还提供了技术交流群邀请函,并介绍相关从业者深造、就业和研究方面的开放交流平台。

北京大学董豪老师课题组提出DexGarmentLab仿真平台和HALO泛化策略,解决柔性衣物操作中的数据依赖、物理真实性不足及算法泛化能力弱等问题。
