
强化学习

京东集团算法总监韩艾将在 AICon 北京站分享基于强化学习的异构多智能体联合进化算法

AICon 大会即将召开,韩艾将分享基于强化学习的异构多智能体联合进化算法。大会涵盖多模态应用、推理性能优化等多个专题论坛,为 AI 技术开发者提供前沿洞察与实践经验。
unsloth制作了一份关于大模型强化学习的完整指南
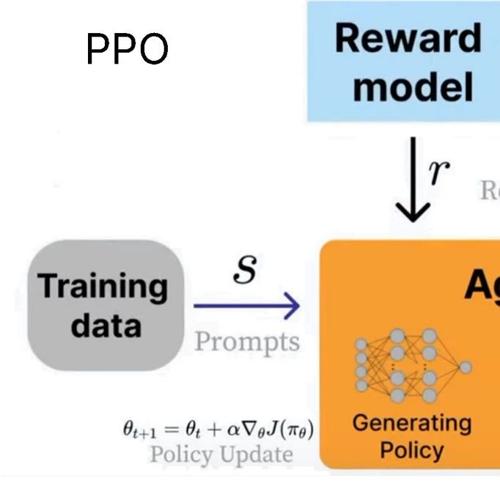
Unsloth发布了关于大模型强化学习的完整指南,涵盖目标、关键作用及在AI代理中的应用等内容,并提供了GRPO、RLHF、DPO和奖励函数的相关信息。

Kimi-Dev:强大的开源编程LLM,助力软件开发任务
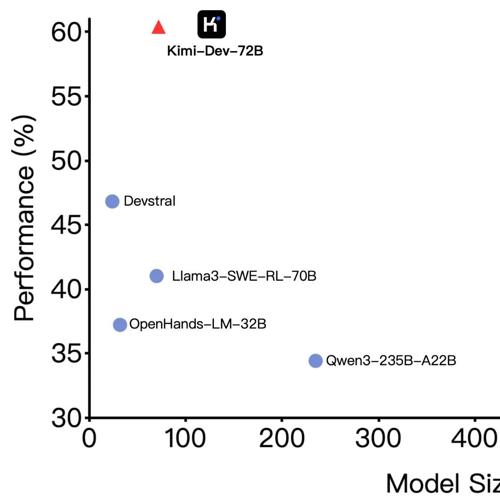
Kimi-Dev 是一款强大的开源编程LLM,性能超越其他开源模型,在SWE-bench Verified上达到60.4%;支持本地部署和Hugging Face使用,并通过大规模强化学习优化解决方案的准确性和鲁棒性。

炸裂!MiniMax推出全球最长上下文推理模型M1:512张H800三周完成训练,成本仅54万美金

MiniMax举办开源周活动,正式发布最新推理模型MiniMax-M1,支持100万token输入与8万token输出,参数量达4560亿。通过大规模强化学习训练,仅耗资53.47万美元。该模型采用混合注意力架构和闪电注意力机制,显著提升推理效率,并在复杂任务中表现突出。

MSRA清北推出强化预训练!取代传统自监督,14B模型媲美32B

微软亚洲研究院联合清华大学、北京大学提出RPT预训练范式,将强化学习深度融入预训练阶段,通过生成思维链推理序列和使用前缀匹配奖励来提升模型预测准确度。
103K「硬核」题,让大模型突破数学推理瓶颈

本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。