
Claude 3.7、QwQ-Max-Preview等推理大模型发布跟踪:兼看大模型逻辑推理技术总结及几点思考

近日推理大模型相关前沿回顾包括Claude 3.7的发布,Qwen的QwQ模型开源,FlashMLA的开源及PaliGemma 2 Mix模型的开源。文章还总结了大模型逻辑推理技术,并提出了一些值得思考的问题。
近日推理大模型相关前沿回顾包括Claude 3.7的发布,Qwen的QwQ模型开源,FlashMLA的开源及PaliGemma 2 Mix模型的开源。文章还总结了大模型逻辑推理技术,并提出了一些值得思考的问题。

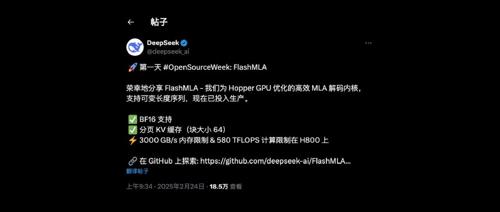
DeepSeek发布首个开源项目FlashMLA,专为英伟达Hopper GPU设计,实现了高效MLA解码内核,提供3000GB/s内存带宽和580TFLOPS计算性能,已在GitHub上吸引5000+星。

DeepSeek开源周启动,FlashMLA项目因高效MLA解码内核受到关注。此项目优化了可变长度序列处理,并显著降低了GPU内存使用和计算成本。

首个开源代码库FlashMLA针对英伟达Hopper架构GPU优化,支持BF16数据类型和分页KV缓存,提供高性能计算与内存吞吐,在内存限制配置下推理性能提升2-3倍,计算限制配置下提升约2倍。

今天正式推出DeepSeek开源周,FlashMLA在极短时间内收获超过3.5K Star。它是针对HopperGPU优化的高效MLA解码内核,支持变长序列处理。FlashMLA通过优化减轻了内存占用并加速计算过程。
今天是2025年02月24日,星期一。文章讨论了mobile agent的思考和开源进展,包括MoE小模型Moonlight-16B-A3B、Qwen2.5-VL及deepseek开源周day1开源FlashMLA等项目。此外还介绍了RAG在写作场景中的应用进展。
DeepSeek开源了一款针对Hopper GPU的FlashMLA内核,专门优化多头潜在注意力(MLA)解码阶段,支持变长序列输入,已在Github上获得300多个Star。
DeepSeek本周开源了一款用于Hopper GPU的高效MLA解码内核FlashMLA,主要用于减少推理过程中的KV Cache成本。该项目上线45分钟后收获超过400星,并且得到了广泛好评。

DeepSeek开源首个项目FlashMLA,针对英伟达Hopper GPU优化MLA解码内核,提升LLM模型在H800上的性能。
