
Transformer


心影随形创始人刘斌新:做不跟用户抢时间的AI产品丨中国AIGC产业峰会

刘斌新分享了他创立的心影随形科技,通过AI技术解决游戏场景中的社交痛点,产品定位为‘陪伴’而非抢占时间。他们发现用户在玩游戏时需要朋友一起玩的需求,并希望通过AI让游戏伙伴理解玩家情绪,提供额外的情绪价值。
AI版本宝可梦冲榜上全球前10%!一次性「吃掉」10年47.5万场人类对战数据

德州大学奥斯汀分校的研究团队使用Transformer和离线强化学习训练出一个宝可梦对战智能体,它能利用人类历史对战数据进行学习,并在全球排名中取得前10%的成绩。
纯自回归图像生成模型开源来了,复旦联手字节seed共同捍卫自回归

基于Transformer的自回归视觉生成模型在图像生成领域的表现受到了质疑。然而,复旦大学和字节Seed的研究者们提出了一种新方法SimpleAR,在0.5B参数规模下实现了高质量图像的生成,并通过优化训练过程提升了模型的效果。
微软开源实时交互模型:提升Agent动态复杂处理能力

微软研究院开源了实时交互世界模型MineWorld,以Transformer为核心结合《我的世界》。MineWorld参数量少于Oasis,在多方面表现更优,包括视频质量、可控性和推理速度等方面。MineWorld架构由Transformer解码器、视觉标记器和动作标记器组成,实现高效并行解码算法提高生成效率。
这本书为啥全网都在追?我看了3页就明白了!
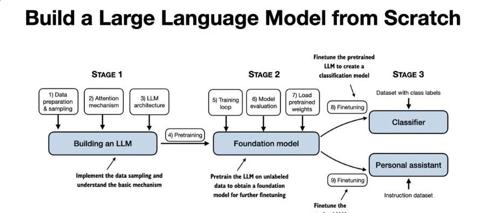
Sebastian Raschka 的《从零构建大模型》是一本帮助读者理解并实战大模型开发的书。通过直接、清晰的教学方式,本书涵盖了从数据准备到模型部署的全流程,适合Python基础和普通笔记本硬件条件的开发者。

U-Net和ViT凑一块,会发生什么?U-REPA:精准对齐Diffusion U-Net与ViT特征空间,训练提速42%
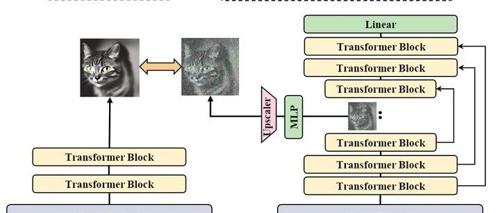
U-Net 架构对齐到 ViT(Vision Transformer)特征空间
的新方法
U-REP
