多模态语音表征新突破!CoGenAV:高效、鲁棒、通用的语音识别“利器” 2025年6月11日14时 作者 小兵的AI视界 通义联合深圳技术大学推出的CoGenAV模型通过融合音频和视觉信息,显著提升了语音识别和处理性能。仅需223小时标记数据即可训练,展现出极高的数据效率,并在多种语音处理任务中表现出色。
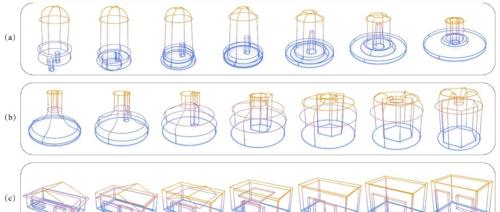
SIGGRAPH 2025 CLR-Wire:曲线框可生成?可交互?深大VCC带你见证魔法 2025年5月29日8时 作者 机器之心 维曲线框结构统一编码到连续的潜空间中,解决了传统方法难以同时有效捕捉线框几何和拓扑信息的难题。这一创
4万多名作者挤破头,CVPR 2025官方揭秘三大爆款主题, 你卷对方向了吗? 2025年5月28日16时 作者 机器之心 CVPR 2025三大热门方向:3D技术、图像与视频合成和多模态学习,论文提交数量创历史新高。
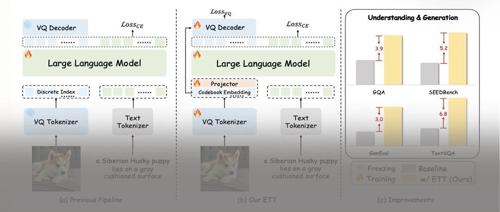
ETT:打破原生多模态学习视觉瓶颈,重塑视觉tokenizer优化范式 2025年5月27日16时 作者 机器之心 本文提出了一种新的端到端视觉 tokenizer 调优方法 ETT,解决了传统方法存在的问题,显著提升了多模态任务的性能。
简单却强大!端到端视觉Tokenizer调优让多模态任务性能飙升!智源&卢湖川团队等发布ETT 2025年5月20日23时 作者 极市干货 本文 提出了一种端到端视觉分词器调优方法ETT,通过联合优化分词器的重建目标和下游任务目标,并利用码
重磅发布 复旦《大规模语言模型:从理论到实践(第2版)》全新升级,聚焦AI前沿 2025年4月28日16时 作者 机器之心 业 技术书 ,更是 AI时代不可或缺的知识工具书。 任何人 都能在本书中找到属于自己的成长路径。 在
OpenAI、谷歌等一线大模型科学家公开课,斯坦福CS 25春季上新! 2025年4月26日16时 作者 机器之心 斯坦福 CS25 课程邀请多位 AI 研究者讲解 Transformer,涵盖最新突破与未来展望。