怎么学习使用大模型?论大模型和汽车的关系

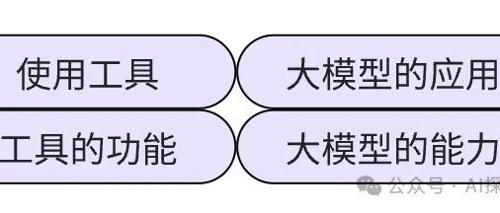
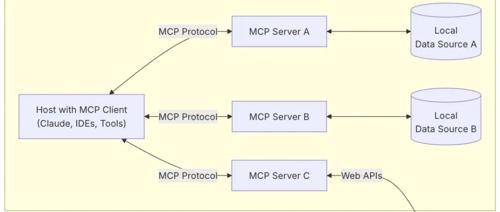
学习和使用大模型需要掌握提示词技术(Prompt Engineering),类似于学会开车技能。理解并应用大模型的功能,比如内容生成、自然语言理解和逻辑推理等,通过RAG、Function call或MCP协议与大模型交互。选择适合的模型,并根据需求优化提示词以达到最佳效果。
学习和使用大模型需要掌握提示词技术(Prompt Engineering),类似于学会开车技能。理解并应用大模型的功能,比如内容生成、自然语言理解和逻辑推理等,通过RAG、Function call或MCP协议与大模型交互。选择适合的模型,并根据需求优化提示词以达到最佳效果。
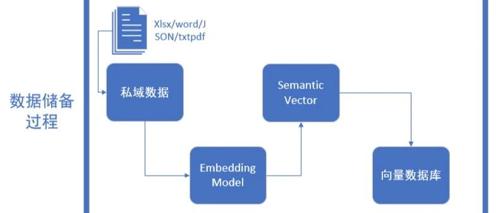
关于RAG在实际场景中的应用,重点讨论了文档处理和高效检索的问题。文档处理涉及多样化和复杂的格式,需要拆分和识别文本、图片和图表等不同内容类型。高效的检索则需利用多种匹配方式(精确字符匹配与语义匹配),通过多路召回策略综合考虑多个维度的数据来优化结果。

近年来我国智能座舱发展迅速,但安全问题频出。为填补行业空白,《智能网联汽车座舱产品安全评价规范》团体标准正在制定中,涵盖多项安全评价指标和方法,旨在提高产品设计的安全性与可靠性。
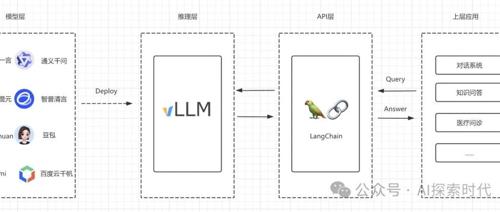
随着大语言模型(LLM)应用增加,企业级部署和推理模型成为焦点。多种前端框架如Transformers、ModelScope等被对比分析,帮助选择最适合的解决方案。
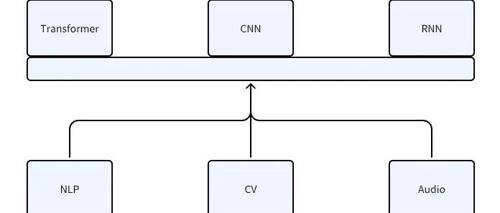
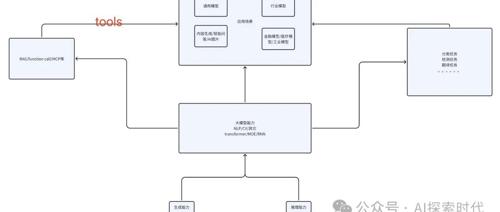
梳理了大模型体系构成和应用关系,介绍了神经网络作为机器学习的一种深度学习方式的基本原理及其在自然语言处理、计算机视觉等领域的结合应用,并阐述了不同架构如Transformer、RNN的工作机制,强调了神经网络并非万能及需要具体任务场景来发挥作用。
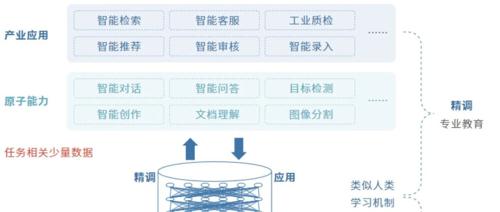
文章介绍了大模型分类的复杂性及用户和技术两个角度的大模型应用,并强调了实际需求的重要性,建议根据任务需求选择合适的模型,同时指出当前大模型评估标准缺失的问题,鼓励多尝试和研究。
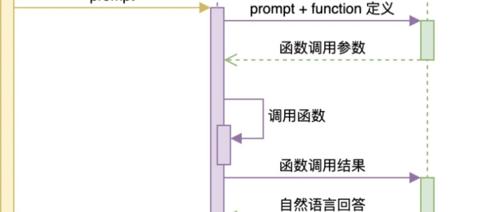
最近在研究大模型智能体过程中遇到的问题之一是意图识别不准确,影响了Agent的质量和效果。解决方法包括明确描述函数功能、使用多轮对话增强理解能力、利用分类模型进行意图识别及设置规则引擎兜底等。