
强化学习

王炸组合:微信接入满血DeepSeek R1,背后的Agentic RAG技术~

微信灰度接入DeepSeek R1,支持更全面的回答。DeeSeek-R1采用Agentic RAG方式接入,可以设计通用AI Agentic框架,并结合官方Prompt和搜索接入实现。

不蒸馏R1也能超越DeepSeek,上海 AI Lab 用RL突破数学推理极限

上海AI Lab提出的新方法OREAL利用基于结果奖励的强化学习超越了DeepSeek,无需超大规模模型蒸馏。通过模仿正样本、偏好负样本并关注关键步骤,实现了数学推理任务上的显著提升,并开源训练数据和模型以促进研究对比。
从PPO到GRPO,DeepSeek-R1做对了什么?

本周通讯解读了三个值得关注的技术与行业动态。DeepSeek-R1 在强化学习中采用GRPO替代PPO,减少人类标注数据并设计精妙奖励机制;ARK展望AI对经济的影响;Kimi 1.5和DeepSeek-R1均使用Rule-based Reward提升模型推理能力。


赶紧放弃强化学习?!Meta 首席 AI 科学家杨立昆喊话:当前推理方式会“作弊”,卷大模型没有意义!

这样的困境:它们基于深度学习架构,通过在大规模数据上进行预训练、调整参数,看似构建起了对世界的“理解
GSM8K-RLVR:用强化学习提升语言模型的数学解题能力
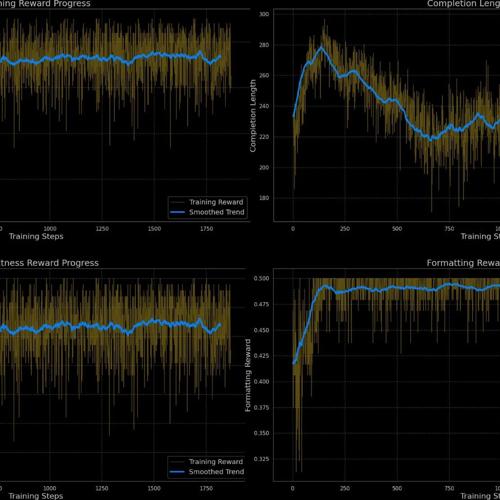
GSM8K-RLVR利用强化学习提升语言模型数学解题能力,Qwen2.5-Math-1.5B模型准确率从70.66%提升至77.33%,简化提示格式无需复杂标签。
让 LLM 来评判 | 奖励模型相关内容

奖励模型通过学习人工标注的成对 prompt 数据来预测分数,用于评估语言模型的表现。它们比传统LLM评估模型更快速且具有确定性,但需要特定微调和考虑位置偏差影响。