
世界模型

对话阶跃星辰姜大昕:成立两年已发布22款模型,DeepSeek证明投流模式是不成立的|

阶跃星辰在北京举行媒体沟通会,预计发布满血版推理模型Step R1及先进图片编辑模型。创始人姜大昕强调多模理解生成一体化是建立世界模型的最佳路径,未来将聚焦智能终端Agent和AGI方向。

DeepMind闭关修炼「我的世界」,自学成才挖钻登Nature!人类玩家瑟瑟发抖

谷歌DeepMind的DreamerV3在《我的世界》中无需人类数据自主完成钻石收集任务,标志着AI向通用人工智能(AGI)又迈进了一步。

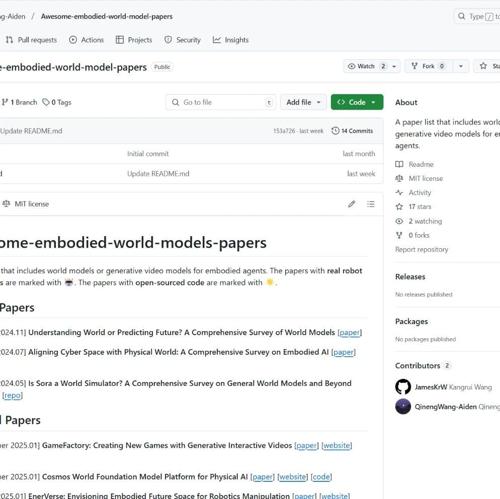
港科大、地平线提出DrivingWorld:基于视频GPT构建自动驾驶世界模型

港科大与地平线联合提出DrivingWorld模型,采用基于自回归架构的方法实现精准的自动驾驶世界模型。通过空间-时间先解耦后融合机制和next-state预测策略,实现超长时序视频生成及可控性提升。

智源发布2025十大AI技术趋势:从Agent到Agentic AI

智源研究院发布2025年人工智能技术及应用趋势,包括AI4S推动科学研究、具身智能元年、多模态大模型实现高效、RL+LLMs提升基础模型性能等。
谷歌新动作!Sora前负责人带队打造“现实世界模拟器”,AI领域再掀波澜

谷歌组建新团队开发模拟现实世界的人工智能模型,领头人蒂姆·布鲁克斯曾是OpenAI视频生成器Sora的联合负责人,目标是在DeepMind推进通用人工智能发展。